How can I help you?
OCR Processor Troubleshooting
31 Mar 202615 minutes to read
Tesseract has not been initialized exception
| Exception | Tesseract has not been initialized exception. |
|---|---|
| Reason | The exception may occur if the tesseract binaries and tessdata files are unavailable on the provided path. |
| Solution1 |
Set proper tesseract binaries and tessdata folder with all files and inner folders. The tessdata folder name is case-sensitive and should not change.
|
| Solution2 | Ensure that your data file version is 3.02 since the OCR processor is built with the Tesseract version 3.02. |
Exception has been thrown by the target of an invocation
| Exception | Exception has been thrown by the target of an invocation. |
|---|---|
| Reason | If the tesseract binaries are not in the required structure. |
| Solution |
To resolve this exception, ensure the tesseract binaries are in the following structure.
The tessdata and tesseract binaries folder are automatically added to the bin folder of the application. The assemblies should be in the following structure. 1.bin\Debug\net7.0\runtimes\win-x64\native\leptonica-1.80.0.dll,libSyncfusionTesseract.dll 2.bin\Debug\net7.0\runtimes\win-x86\native\leptonica-1.80.0.dll,libSyncfusionTesseract.dll |
| Reason 1 | An exception may occur due to missing or mismatched assemblies of the Tesseract binaries and Tesseract data from the OCR processor. |
| Reason 2 | An exception may occur due to the VC++ 2015 redistributable files missing in the machine where the OCR processor takes place. |
| Solution |
Install the VC++ 2015 redistributable files in your machine to overcome an exception. So, please select both file and install it.
Refer to the following screenshot: 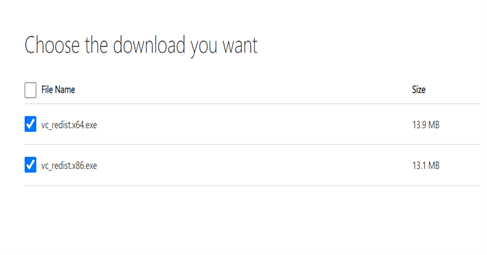
Please find the download link Visual C++ 2015 Redistributable file, Visual C++ 2015 Redistributable file |
Can’t be opened because the developer’s identity cannot be confirmed
| Exception | Can't be opened because the developer's identity cannot be confirmed. |
|---|---|
| Reason | This error may occur during the initial loading of the OCR processor in Mac environments. |
| Solution | To resolve this issue, refer this link for more details. |
The OCR processor doesn’t process languages other than English
| Exception | The OCR processor doesn't process languages other than English. |
|---|---|
| Reason | This issue may occur if the input image has other languages. The language and tessdata are unavailable for those languages. |
| Solution |
The essential® PDF supports all the languages the Tesseract engine supports in the OCR processor.
The dictionary packs for the languages can be downloaded from the following online location: https://code.google.com/p/tesseract-ocr/downloads/list It is also mandatory to change the corresponding language code in the OCRProcessor.Settings.Language property. For example, to perform the optical character recognition in German, the property should be set as "processor.Settings.Language = "deu";" |
OCR fails in .NET Core WinForms but Works in .NET Framework
| Exception | OCR processing works correctly in a .NET Framework WinForms application but fails to produce any output when the same logic is used in a .NET Core WinForms application. The application runs without throwing any exceptions, but no text is recognized from the PDF or image. |
|---|---|
| Reason | The root cause is a platform-specific dependency mismatch. The Tesseract binaries required for .NET Framework are different from those required for .NET Core. Even if the binaries are present in the output folder, using Framework-specific binaries in a .NET Core project causes the OCR process to fail silently. |
| Solution |
Ensure your .NET Core project uses the correct Tesseract binaries built for .NET Core: 1.Install the Correct NuGet Package: Reference the Syncfusion.PDF.OCR.Net.Core NuGet package in your .NET Core project. 2.Verify the Tesseract Binaries: Confirm that the correct binaries are copied to your output directory: a.Extract the Syncfusion.PDF.OCR.Net.Core NuGet package. b.Copy the appropriate runtimes folder from the extracted package into your project's output directory (e.g., bin/Debug/net6.0-windows/). |
Text does not recognize properly when performing OCR on a PDF document with low-quality images
| Issue | Text does not recognize properly when performing OCR on a PDF document with low-quality images |
|---|---|
| Reason | The presence of low quality images in the input PDF document may be the cause of this issue. |
| Solution |
By using the best tessdata, we can improve the OCR results. For more information, please refer to the links below. https://github.com/tesseract-ocr/tessdata_best Note: For better performance, kindly use the fast tessdata which is mentioned in below link,https://github.com/tesseract-ocr/tessdata_fast |
OCR not working on Mac: Exception has been thrown by the target of an invocation
| Issue | Syncfusion.Pdf.PdfException: Exception has been thrown by the target of an invocation" in the Mac machine. |
|---|---|
| Reason | The problem occurs due to a mismatch in the dependency package versions on your Mac machine. |
| Solution | To resolve this problem, you should install and utilize Tesseract 5 on your Mac machine. Refer to the following steps for installing Tesseract 5 and integrating it into an OCR processing workflow.
1.Execute the following command to install Tesseract 5. If the "brew" is not installed on your machine, you can install it using the following command. 2.Once Tesseract 5 is successfully installed, you can configure the path to the latest binaries by copying the location of the Tesseract folder and setting it as the Tesseract binaries path when setting up the OCR processor. Refer to the example code below: 3.Add the TessDataPath from bin folder. Refer to the example code below: |
Method PerformOCR() causes problems and ignores the tesseract files under WSL.
| Issue | Method PerformOCR() causes problem and ignores the tesseract files under WSL |
|---|---|
| Reason | Tesseract binaries in WSL are missing. |
| Solution | To resolve this problem, you should install and utilize Leptonica and Tesseract on your machine. Refer to the following steps for installing Leptonica and Tesseract,
1. Install the leptonica. 
2.Install the tesseract. 
3. Copy the binaries (liblept.so and libtesseract.so) to the missing files exception folder in the project location. |
OCR not working on Linux: Exception has been thrown by the target of an invocation
| Issue | Syncfusion.Pdf.PdfException: Exception has been thrown by the target of an invocation" in the Linux machine. |
|---|---|
| Reason | The problem occurs due to the missing prerequisites dependencies on your Linux machine. |
| Solution |
To resolve this problem, you should install all required dependencies in your Linux machine. Refer to the following steps to installing the missing dependencies.
Step 1: Execute the following command in terminal window to check dependencies are installed properly.
Step 1: |
OCR not working on Docker net 8.0: Exception has been thrown by target of an invocation.
| Exception | OCR not working on Docker net 8.0: Exception has been thrown by target of an invocation. |
|---|---|
| Reason | The reported issue occurs due to the missing prerequisite dependencies packages in the Docker container in .NET 8.0 version. |
| Solution |
We can resolve the reported issue by installing the tesseract required dependencies by using Docker file. Please refer the below commands.
|
Default path reference for Syncfusion® OCR packages
When installing the Syncfusion® OCR NuGet packages, the tessdata and tesseract path binaries are copied into the runtimes folder. The default binaries path references are added in the package itself, so there is no need to set the manual path.
If you are facing any issues with default reference path in your project. Kindly manually set the Tesseract and Tessdata path using the TessdataPath and TesseractPath in OCRProcessor class. You can find the binaries in the below project in your project location.
| Tessdata path | Tessdata default path reference is common for all platform. You can find the tessdata in below path in your project. "bin\Debug\net6.0\runtimes\tessdata" |
|---|---|
| Tesseract Path |
Tesseract binaries are different based on the OS platform and bit version . You can find the tesseract path in below path in your project.
Windows Platform: bin\Debug\net6.0\runtimes\win-x86\native (or) bin\Debug\net6.0\runtimes\win-x64\native Linux: bin\Debug\net6.0\runtimes\linux\native Mac: bin\Debug\net6.0.\runtimes\osx\native |
System.NullReferenceException in Azure linux VM
| Exception | System.NullReferenceException in Azure linux VM |
|---|---|
| Reason | The problem occurs while extracting the Image from PDF without a Skiasharp dependency in a Linux environment. |
| Solution |
Installing the following Skiasharp NuGet for the Linux environment will resolve the System.NullReferenceException while extracting the Images in Linux. Please find the NuGet link below, NuGet: https://www.nuget.org/packages/SkiaSharp.NativeAssets.Linux.NoDependencies/2.88.6 |
IIS Fails to Load Tesseract OCR DLLs
| Exception | The application failed to load Tesseract OCR DLLs when hosted on IIS, resulting in the error: Could not find a part of the path 'C:\inetpub\wwwroot\VizarCore\x64'. |
|---|---|
| Reason | * IIS couldn't load the required Tesseract and Leptonica DLLs because some system components were missing. * The Visual C++ Redistributables for VS2015-VS2022 (x86 and x64) were not installed. * IIS on a 64-bit server needs both redistributables to load native libraries correctly. * The application's folder paths and permissions were not properly set up for OCR binaries. |
| Solution |
Installed Required Redistributables Installed both VC_redist.x86 and VC_redist.x64 for VS2015-VS2022 on the IIS server. Updated Server Applied all available Windows updates (including cumulative and Defender updates) to ensure system stability. Configured Application Paths Set default paths for OCR binaries: * C:\inetpub\wwwroot\myapp\Tesseractbinaries * C:\inetpub\wwwroot\myapp\tessdata Set Proper Permissions Ensured IIS_IUSRS group has Read & Execute and List folder contents permissions on the above directories. Observed Delayed Activation OCR functionality did not activate immediately-likely due to IIS caching or delayed DLL loading-but began working shortly after configuration. |
OCR not working on Azure App Service Linux Docker Container: Exception has been thrown by the target of an invocation
| Exception | Syncfusion.Pdf.PdfException: Exception has been thrown by the target of an invocation while deploying ASP .NET Core applications in Azure App Service Linux Docker Container |
|---|---|
| Reason | when publishing the ASP.NET Core application to the Azure App Service Linux Docker container, only the .so, .dylib, and .dll files are copied from the runtimes folder to the publish folder. Files in other formats are not copied to the publish folder. |
| Solution |
To resolve this problem, the tessdata folder path must be explicitly set relative to the project directory under runtimes/tessdata. The publish folder can be located in your project directory at this path: obj\Docker\publish.
Please refer to the screenshot below: 
|
‘Image stream is null’ exception while performing OCR in AKS (Linux)
| Exception | 'Image stream is null' exception while performing OCR in AKS (Linux)) |
|---|---|
| Reason | This issue typically arises due to insufficient file system permissions for the temporary directory used during OCR processing in an AKS (Azure Kubernetes Service) Linux environment. |
| Solution |
To ensure your Kubernetes workloads have appropriate read, write, and execute permissions on temporary directories, consider the following solutions:
1.Use an EmptyDir Volume for a Writable Temp Directory: Update your deployment YAML to include a writable temporary directory with `emptyDir`: This ensures each pod has its own writable temporary directory, ideal for short-lived, non-persistent data 2.Grant Write Access Using SecurityContext: To ensure your container has permission to write to mounted volumes, add: N> Avoid setting `runAsUser: 0` in production, as running containers as root poses a security risk. 3.Use Persistent Writable Storage (Azure Files Example): If persistent storage is required, configure Azure Files: This setup allows your container to write to a persistent Azure File Share, making it suitable for use cases that require long-term file storage. By applying these configuration changes, you can ensure that your AKS workloads have the necessary write access for operations, while maintaining security and flexibility. |
Does OCRProcessor require Microsoft.mshtml?
| Query | Is Microsoft.mshtml required when using the OCRProcessor in the .NET Framework? |
|---|---|
| Solution | Yes, the Microsoft.mshtml component is required when using the OCRProcessor in .NET Framework applications. We internally rely on this package to parse the hOCR results, which are delivered in HTML format. Because of this, Microsoft.mshtml is necessary for .NET Framework projects that use the OCRProcessor. |