Description and usage of QueryElasticSearch processor:
Queries Elasticsearch using the specified connection properties. Note that the full body of each page of documents will be read into memory before being written to Flow Files for transfer. Also note that the Elasticsearch max_result_window index setting is the upper bound on the number of records that can be retrieved using this query. To retrieve more records, use the ScrollElasticsearchHttp processor.
Tags:
elasticsearch, query, read, get, http
Properties:
In the list below, the names of required properties appear in bold. Any other properties (not in bold) are considered optional. The table also indicates any default values, and whether a property supports the Expression Language Guide.
| Name | Default Value | Allowable Values | Description |
| Elasticsearch URL |
Elasticsearch URL which will be connected to, including scheme (http, e.g.), host, and port. The default port for the REST API is 9200. Supports Expression Language: true |
||
| SSL Context Service |
Controller Service API: SSLContextService Implementation: StandardSSLContextService |
The SSL Context Service used to provide client certificate information for TLS/SSL connections. This service only applies if the Elasticsearch endpoint(s) have been secured with TLS/SSL. | |
| Username |
Username to access the Elasticsearch cluster Supports Expression Language: true |
||
| Password |
Password to access the Elasticsearch cluster Sensitive Property: true Supports Expression Language: true |
||
| Connection Timeout | 5 secs |
Max wait time for the connection to the Elasticsearch REST API. Supports Expression Language: true |
|
| Response Timeout | 15 secs |
Max wait time for a response from the Elasticsearch REST API. Supports Expression Language: true |
|
| Query |
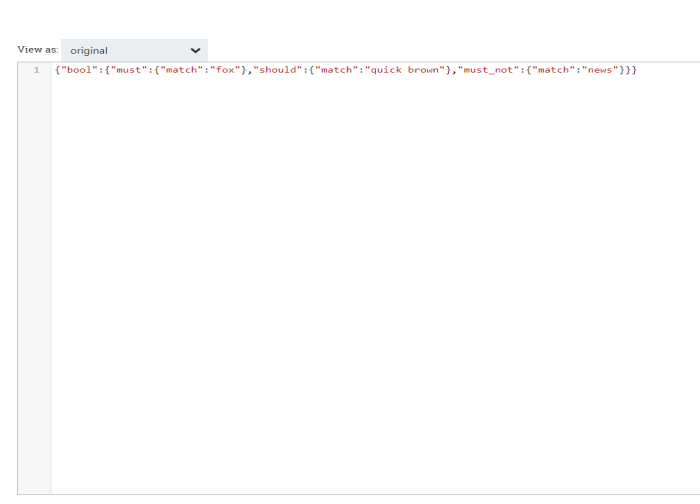
The Lucene-style query to run against ElasticSearch (e.g., genre:blues AND -artist:muddy) Supports Expression Language: true |
||
| Page Size | 20 |
Determines how many documents to return per page during scrolling. Supports Expression Language: true |
|
| Index |
The name of the index to read from. If the property is set to _all, the query will match across all indexes. Supports Expression Language: true |
||
| Type |
The (optional) type of this query, used by Elasticsearch for indexing and searching. If the property is empty, the the query will match across all types. Supports Expression Language: true |
||
| Fields |
A comma-separated list of fields to retrieve from the document. If the Fields property is left blank, then the entire document's source will be retrieved. Supports Expression Language: true |
||
| Sort |
A sort parameter (e.g., timestamp:asc). If the Sort property is left blank, then the results will be retrieved in document order. Supports Expression Language: true |
||
| Limit |
If set, limits the number of results that will be returned. Supports Expression Language: true |
||
| Target | Flow file content |
|
Indicates where the results should be placed. In the case of 'Flow file content', the JSON response will be written as the content of the flow file. In the case of 'Flow file attributes', the original flow file (if applicable) will be cloned for each result, and all return fields will be placed in a flow file attribute of the same name, but prefixed by 'es.result.' |
Relationships:
| Name | Description |
| retry | A FlowFile is routed to this relationship if the document cannot be fetched but attempting the operation again may succeed. Note that if the processor has no incoming connections, flow files may still be sent to this relationship based on the processor properties and the results of the fetch operation. |
| failure | All FlowFiles that cannot be read from Elasticsearch are routed to this relationship. Note that only incoming flow files will be routed to failure. |
| success | All FlowFiles that are read from Elasticsearch are routed to this relationship. |
Reads Attributes:
None specified.
Writes Attributes:
| Name | Description |
| filename | The filename attribute is set to the document identifier |
| es.id | The Elasticsearch document identifier |
| es.index | The Elasticsearch index containing the document |
| es.type | The Elasticsearch document type |
| es.result.* | If Target is 'Flow file attributes', the JSON attributes of each result will be placed into corresponding attributes with this prefix. |
State management:
This component does not store state.
Restricted:
This component is not restricted.
How to configure FetchGCSObject?
Step 1: Drag and drop the QueryElasticSearchHttp processor to canvas.
Step 2: Double click the processor to configure, the configuration dialog will be opened as follows,
Step 3: Check the usage of each property and update those values.
Properties and usage:
Elasticsearch URL: It is used to define elastic search url with hostname and port number. Default port number for the Rest API is 9200.
SSL Context Service: It is used to provide client certificate information for TLS/SSL connections if the Elasticsearch endpoints are secured.
Username: Specifies username to be used for Elasticsearch server.
Password: Specifies password to access the Elasticsearch server.
Connection Timeout: It is used to mention the maximum wait time for connecting with Elasticsearch Rest API.
Response Timeout: It is used to specify maximum wait time for retrieving response from Elasticsearch.
Query: The Lucene-style query to run against ElasticSearch (e.g., genre:blues AND -artist:muddy).
Index: Specifies the name of the index to be used.
Type: Specifies the type of the document (used by Elasticsearch for indexing and searching).
Fields: A comma-separated list of fields to retrieve from the document.
Target: Indicates where the results should be placed.
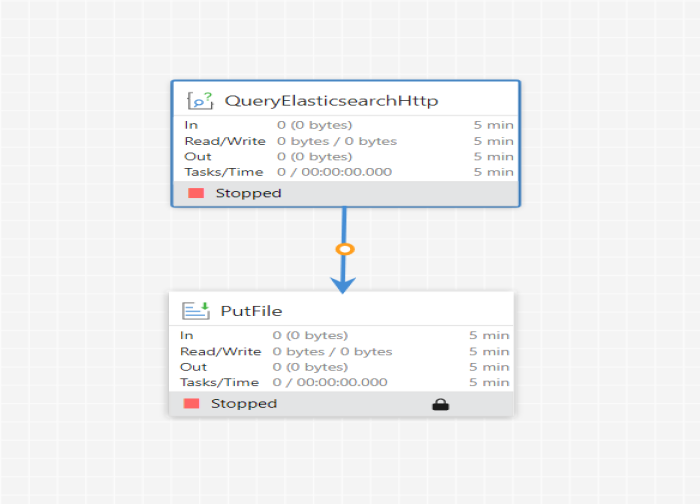
Sample Workflow:
This sample workflow uses the QueryElasticSearchHttp processor to writes the queried Flow Files for transfer in elastic search using data integration platform.
List of processors used in this sample:
|
Processor |
Comments |
| QueryElasticSearchHttp | Reads the full body of each page of documents into memory and writes the queried Flow Files for transfer. |
| PutFile | Writes the contents of a FlowFile to the local file system and act as downstream connection. |
Workflow screenshot
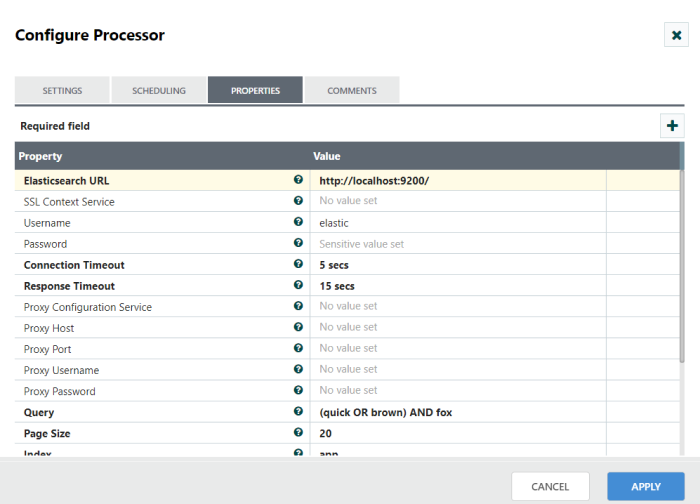
Step 1: Configure QueryElasticSearchHttp processor
Drag and drop the QueryElasticSearchHttp processor to the canvas area. Configure with ElasticSearch URL, username, password and other required properties in configuration dialog as shown in the following screenshots.
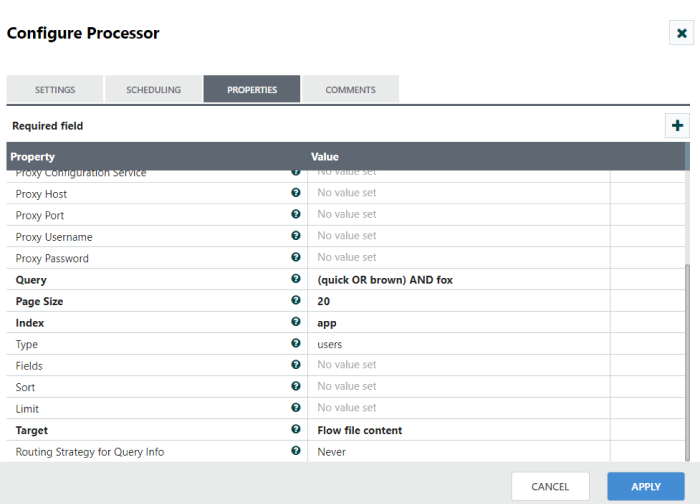
Step 2: Configure PutFile processor
Drag and drop the PutFile processor to the canvas area and PutFile processor is used Writes the contents of a FlowFile to the local file system and act as downstream connection. Configure required properties in configuration dialog as shown in the following screenshot. Also make connection between QueryElasticSearchHttp and PutFile with ‘Success’ relationship.
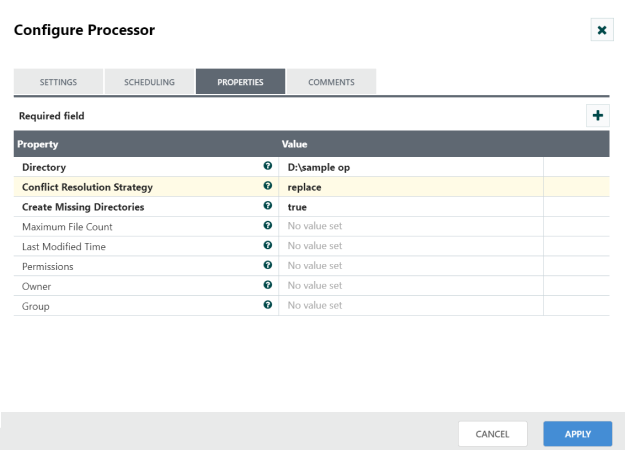
Step 3: Starting workflow
Once all processors are configured, start the workflow. You can see the Flowfiles in Queued Data and in PutFile processor.
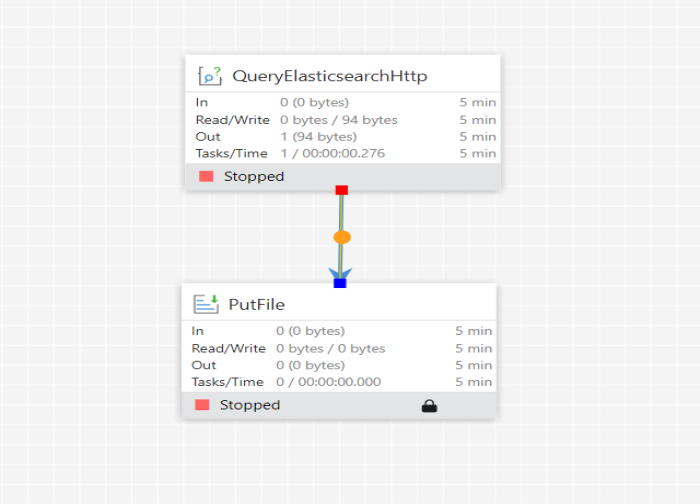
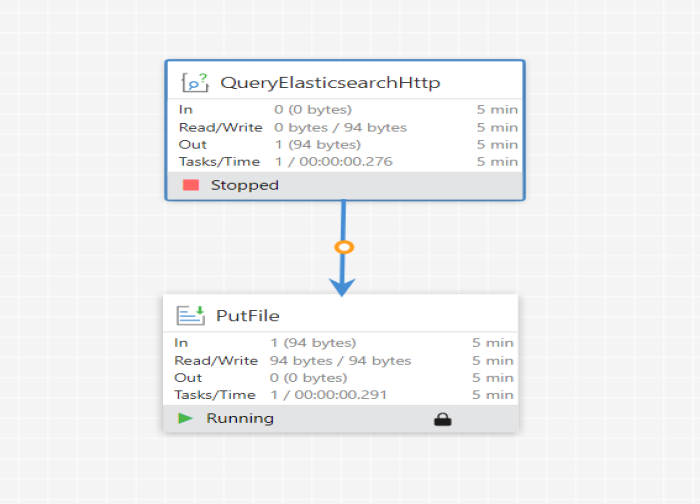
Output Data:
Right Click on the PutFile Processor and select Data preview, you can see the converted JSON Output Data.