Perform OCR in Windows
20 Jan 20253 minutes to read
The Syncfusion® .NET OCR library used to extract text from scanned PDFs and images in Windows Forms application with the help of Google’s Tesseract Optical Character Recognition engine.
Steps to perform OCR on entire PDF document in Windows Forms
Step 1: Create a new Windows Forms application project.
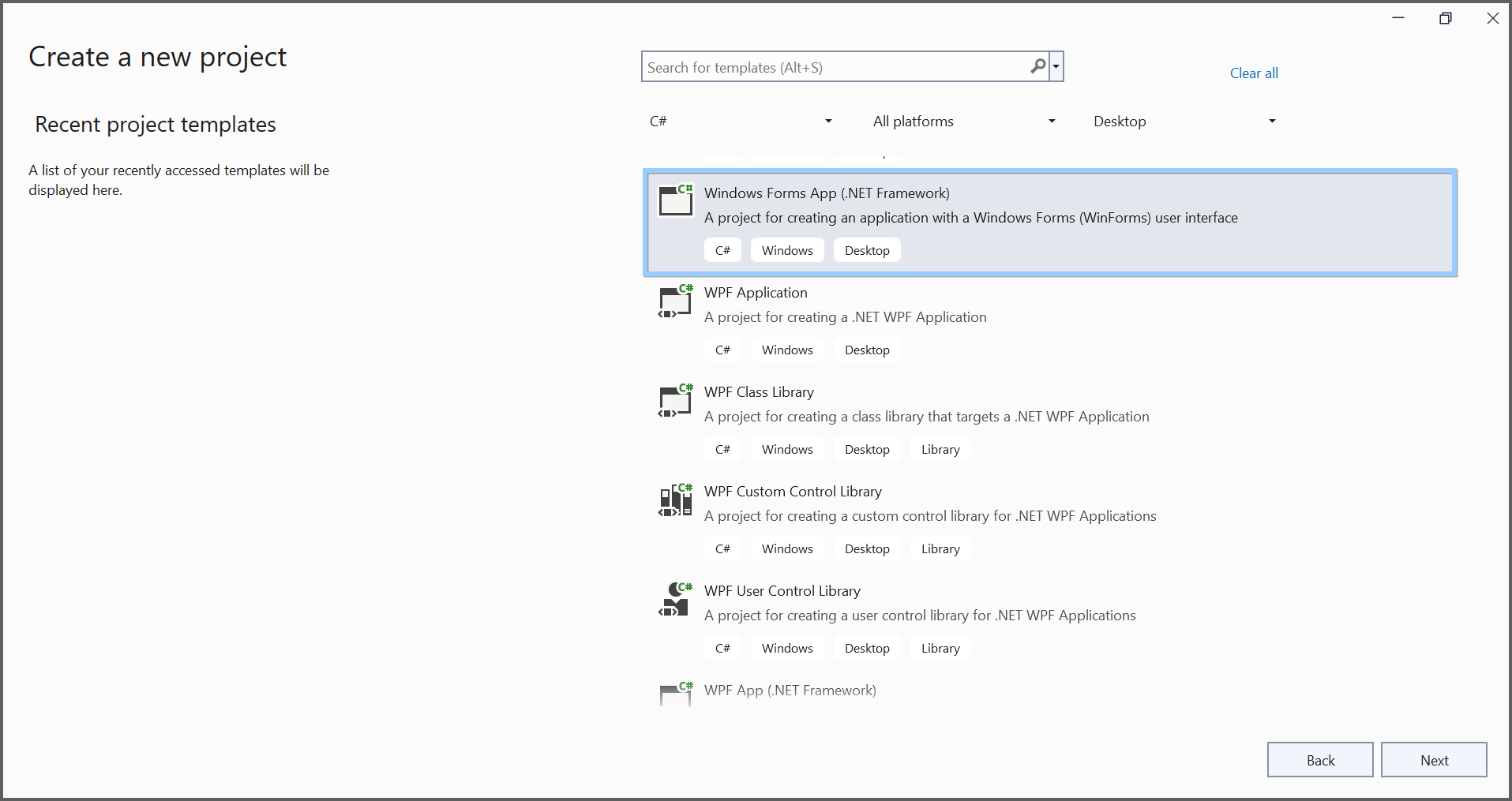
In project configuration window, name your project and select Create.
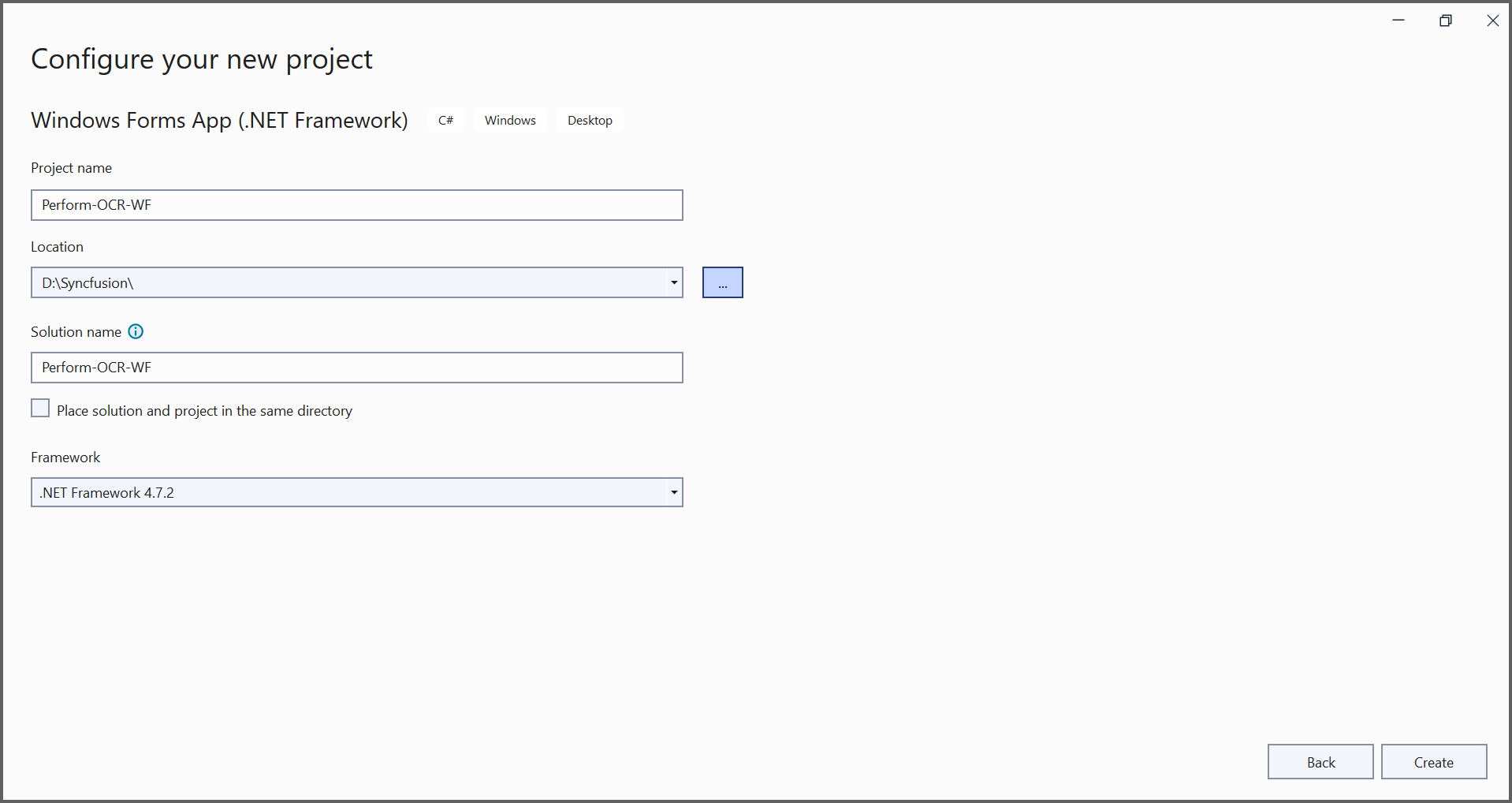
Step 2: Install the Syncfusion.Pdf.OCR.WinForms NuGet package as a reference to your WinForms application from nuget.org.
NOTE
- Beginning from version 21.1.x, the default configuration includes the addition of the TesseractBinaries and Tesseract language data folder paths, eliminating the requirement to explicitly provide these paths.
- Starting with v16.2.0.x, if you reference Syncfusion® assemblies from trial setup or from the NuGet feed, you also have to add “Syncfusion.Licensing” assembly reference and include a license key in your projects. Please refer to this link to know about registering Syncfusion® license key in your application to use our components.
Step 3: Add a new button in Form1.Designer.cs file.
private System.Windows.Forms.Button button1;
private void InitializeComponent()
{
this.button1 = new System.Windows.Forms.Button();
this.SuspendLayout();
//
// button1
//
this.button1.Location = new System.Drawing.Point(284, 162);
this.button1.Name = "button1";
this.button1.Size = new System.Drawing.Size(190, 65);
this.button1.TabIndex = 0;
this.button1.Text = "Perform OCR on entire PDF document";
this.button1.UseVisualStyleBackColor = true;
this.button1.Click += new System.EventHandler(this.btnCreate_Click);
//
// Form1
//
this.AutoScaleDimensions = new System.Drawing.SizeF(9F, 20F);
this.AutoScaleMode = System.Windows.Forms.AutoScaleMode.Font;
this.ClientSize = new System.Drawing.Size(800, 450);
this.Controls.Add(this.button1);
this.Name = "Form1";
this.Text = "Form1";
this.ResumeLayout(false);
}Step 4: Include the following namespaces in the Form1.cs file.
using Syncfusion.OCRProcessor;
using Syncfusion.Pdf.Parsing;Step 5: Create the btnCreate_Click event and add the following code to perform OCR on the entire PDF document using PerformOCR method of the OCRProcessor class.
//Initialize the OCR processor.
using (OCRProcessor processor = new OCRProcessor())
{
//Load an existing PDF document.
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("Input.pdf");
//Set the tesseract version
processor.Settings.TesseractVersion = TesseractVersion.Version4_0;
//Set OCR language to process.
processor.Settings.Language = Languages.English;
//Process OCR by providing the PDF document.
processor.PerformOCR(loadedDocument);
//Save the OCR processed PDF document in the disk.
loadedDocument.Save("OCR.pdf");
loadedDocument.Close(true);
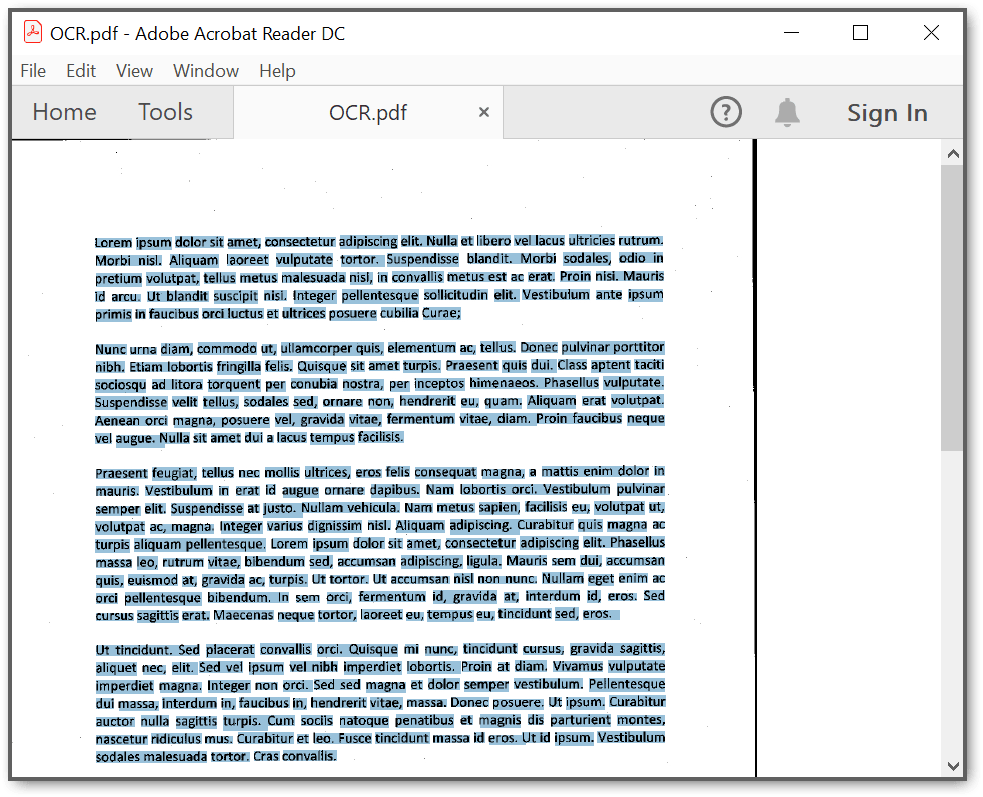
}By executing the program, you will get a PDF document as follows.
A complete working sample can be downloaded from GitHub.
Click here to explore the rich set of Syncfusion® PDF library features.