How can I help you?
Perform OCR in Linux
31 Mar 20263 minutes to read
The Syncfusion® .NET OCR library is used to extract text from scanned PDFs and images in the Linux application with the help of Google’s Tesseract Optical Character Recognition engine.
Pre-requisites
The following Linux dependencies should be installed where the conversion takes place.
sudo apt-get update
sudo apt-get install libgdiplus
sudo apt-get install libc6-dev
sudo apt-get install libleptonica-dev libjpeg62
ln -s /usr/lib/x86_64-linux-gnu/libtiff.so.6 /usr/lib/x86_64-linux-gnu/libtiff.so.5
ln -s /lib/x86_64-linux-gnu/libdl.so.2 /usr/lib/x86_64-linux-gnu/libdl.soSteps to convert HTML to PDF in .NET Core application on Linux
Step 1: Execute the following command in the Linux terminal to create a new .NET Core Console application.
dotnet new console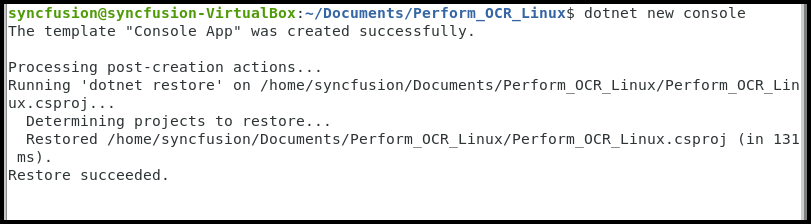
Step 2: Install the Syncfusion.PDF.OCR.Net.Core NuGet package as a reference to your .NET Core application NuGet.org.
dotnet add package Syncfusion.PDF.OCR.Net.Core -v xx.x.x.xx -s https://www.nuget.org/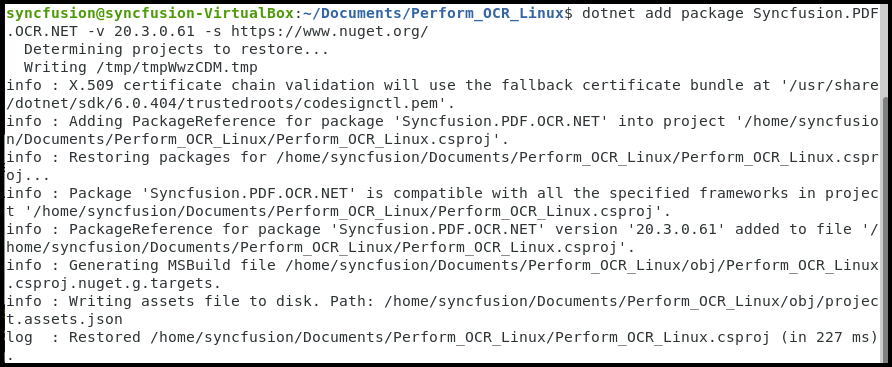
Step 3: Include the following namespaces in Program.cs file.
using Syncfusion.OCRProcessor;
using Syncfusion.Pdf;
using Syncfusion.Pdf.Parsing;NOTE
Beginning from version 21.1.x, the default configuration includes the addition of the TesseractBinaries and Tesseract language data folder paths, eliminating the requirement to explicitly provide these paths.
Step 4: Add code sample to perform OCR on entire PDF document using PerformOCR method of the OCRProcessor class.
string docPath = ("input.pdf");
//Initialize the OCR processor
using (OCRProcessor processor = new OCRProcessor())
{
//Load the PDF document
FileStream stream = new FileStream(docPath, FileMode.Open, FileAccess.Read);
PdfLoadedDocument lDoc = new PdfLoadedDocument(stream);
//Language to process the OCR
processor.Settings.Language = Languages.English;
//Process OCR by providing loaded PDF document, Data dictionary and language
processor.PerformOCR(lDoc);
//Save the OCR processed PDF document in the disk
MemoryStream streamData = new MemoryStream();
lDoc.Save(streamData);
File.WriteAllBytes("Output.pdf", streamData.ToArray());
lDoc.Close(true);
}Step 5: Execute the following command to restore the NuGet packages.
dotnet restore
Step 6: Execute the following command in the terminal to build the application.
dotnet build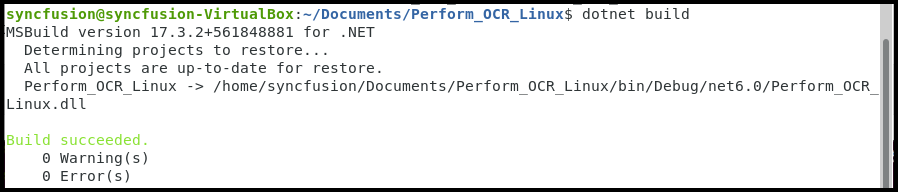
Step 7: Execute the following command in the terminal to run the application.
dotnet run
By executing the program, you will get the PDF document as follows. The output will be saved in parallel to the program.cs file.
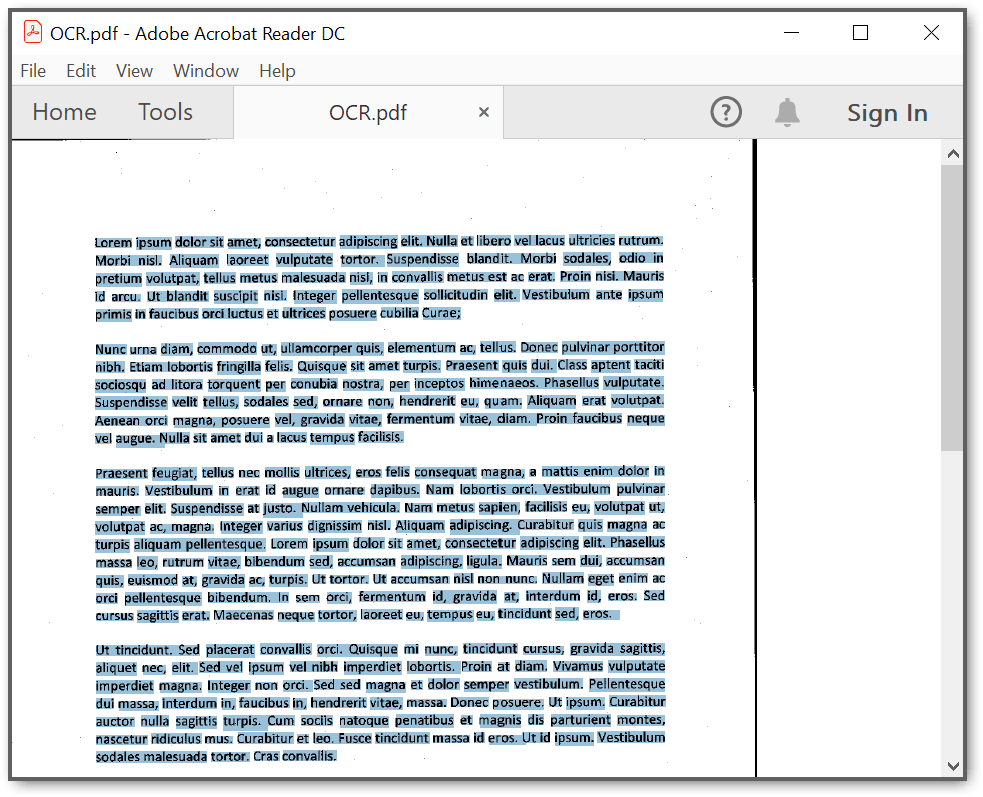
A complete working sample can be downloaded from Github.