Hadoop Cluster Management
Manage Nodes
Add Data Node in Hadoop Cluster
You can scale a running cluster without stopping any Hadoop services. To add additional data nodes into a running cluster, follow the below steps
Step 1: Install Big Data Agent on machines which we want to add as Data node.
Step 2: Click Add Node(s) under Manage nodes dropdown menu in management page of corresponding cluster.
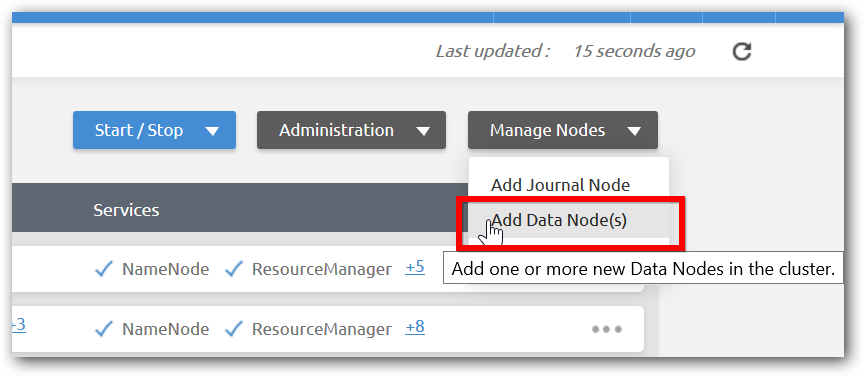
Step 3:Provide IP address or host name of machines which we want to add as Data node. If we want to add more number of data nodes, click the ADD NODE. Then Click Next for validation.

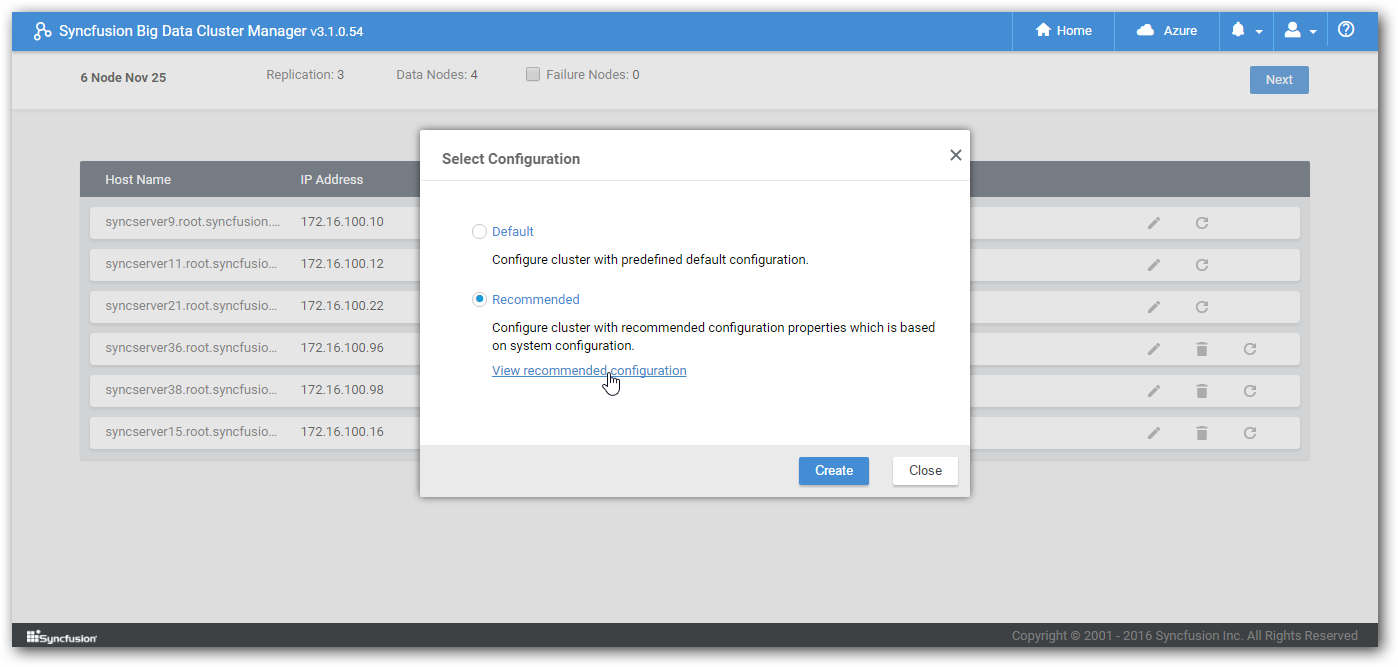
Step 6:After successful validation, click Next to select Configuration type.
Default: All default properties will be set for all cluster nodes.
Recommended: The Cluster Manager will automatically set configuration properties based on hardware specification of nodes such as RAM capacity.
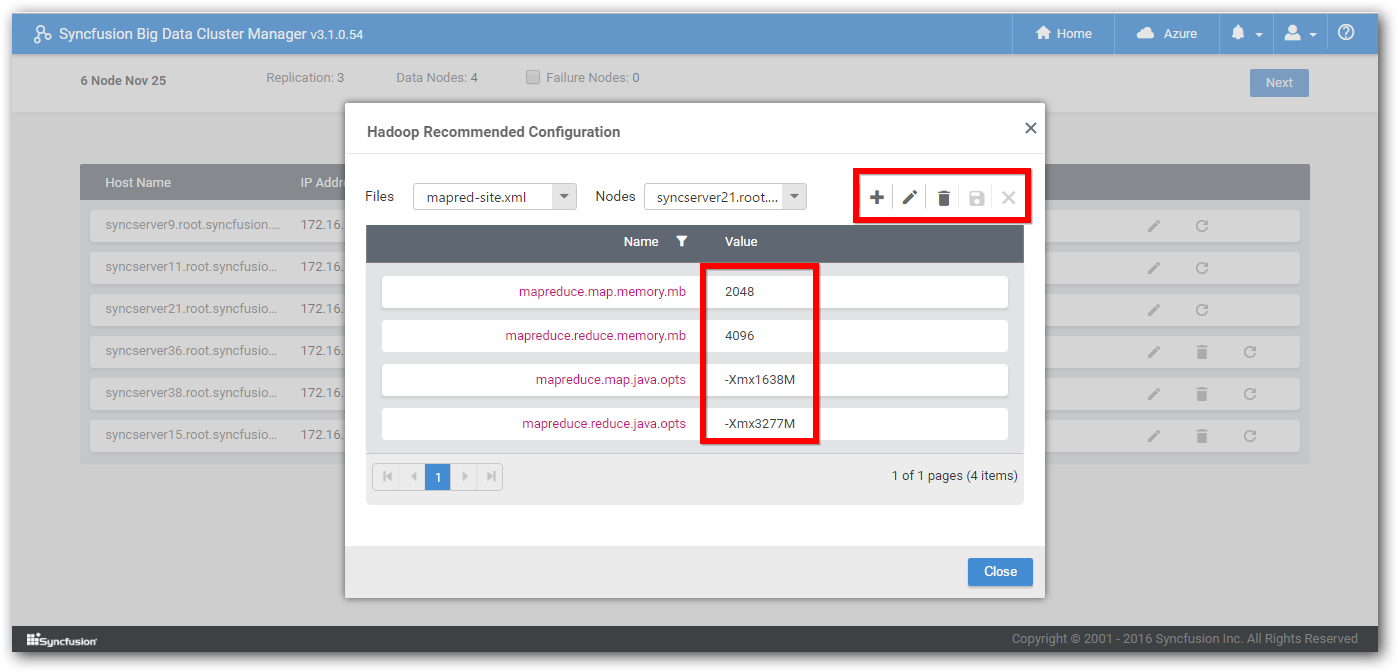
Also you can modify the recommended properties,
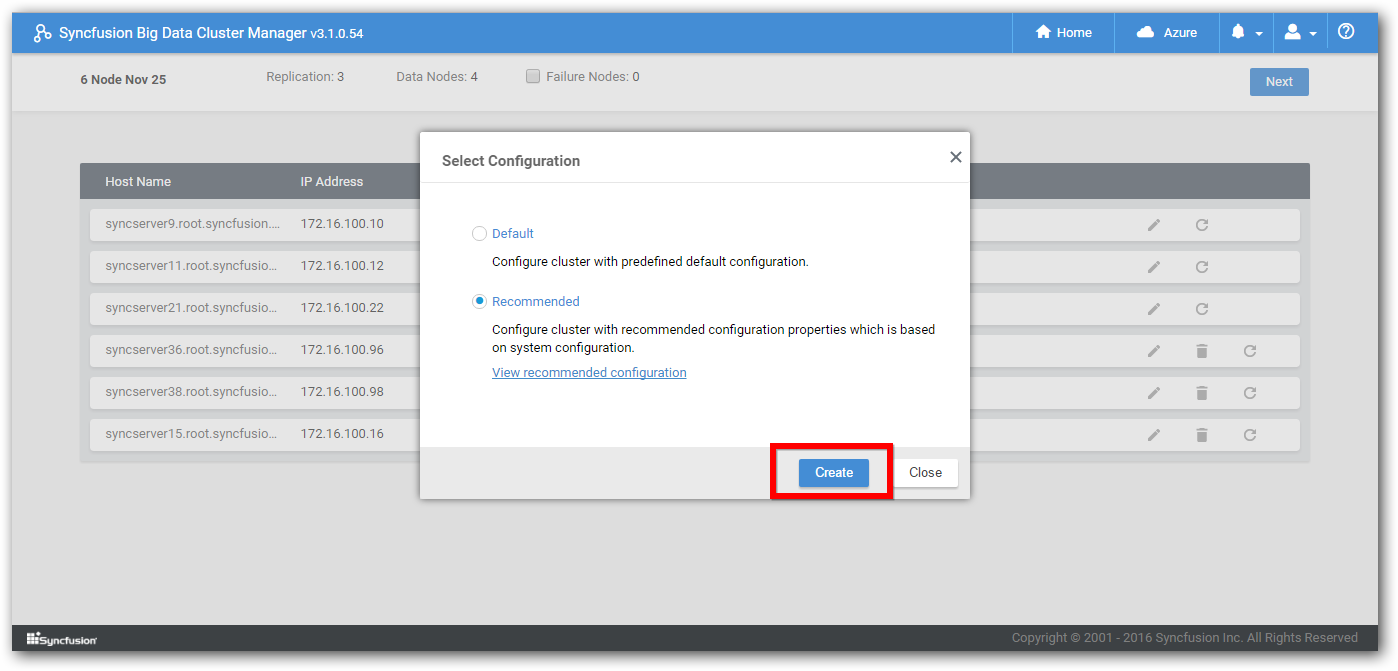
Step 7: Once properties are verified, click Create, so that Cluster Manager starts to transfer packages to Data nodes and services will be automatically started.
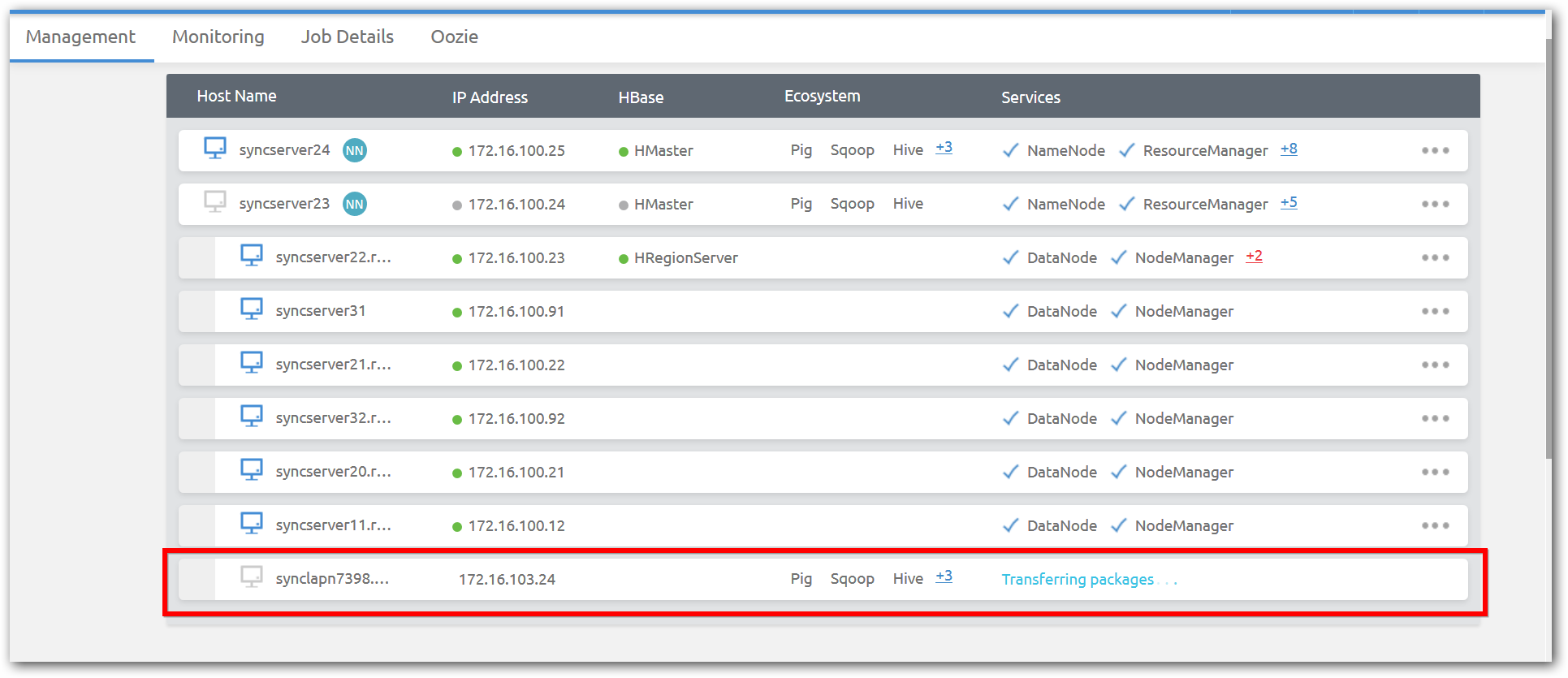
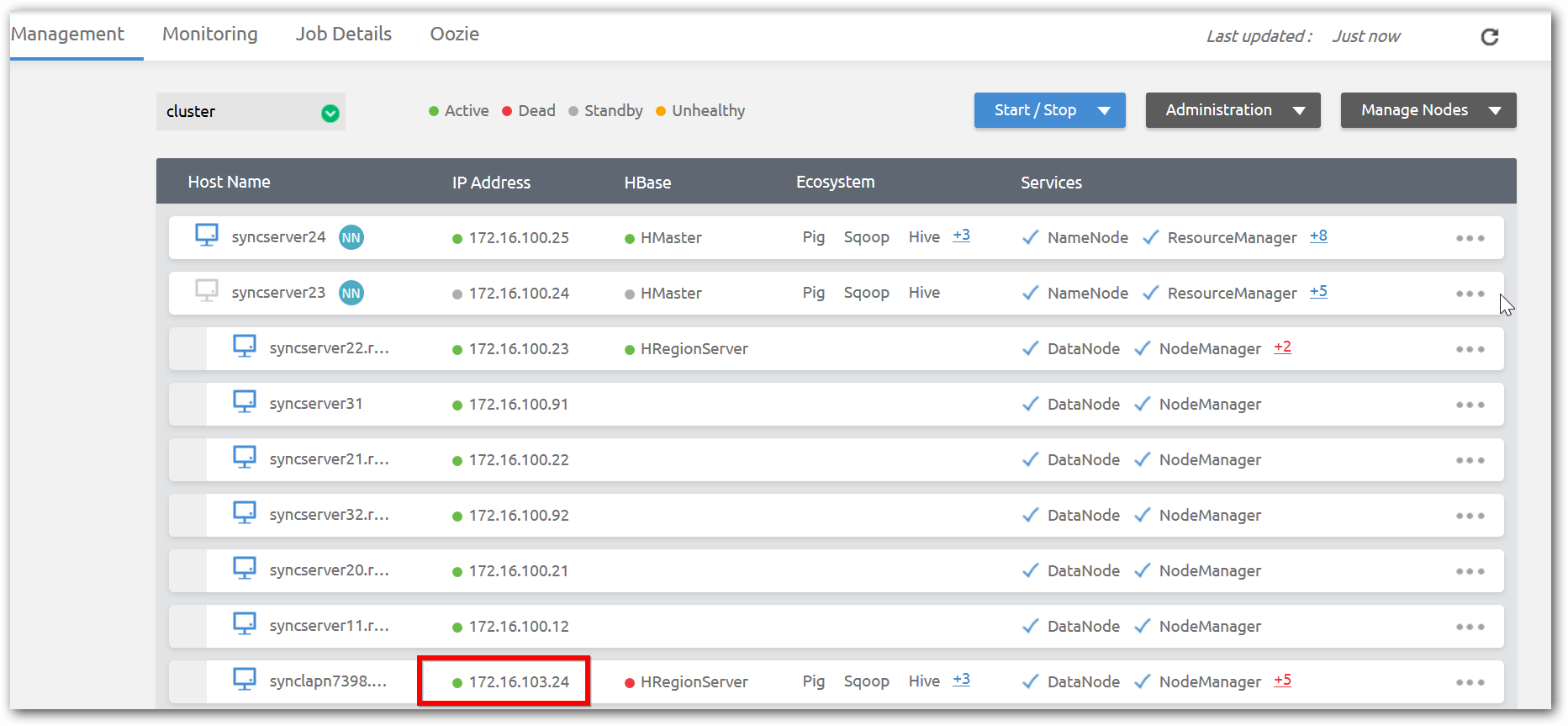
Remove Data node from a Hadoop cluster
To remove data node from a Hadoop cluster follow the below steps.
Step 1:In management page of corresponding a cluster, stop the services of the Data node by selecting the stop node option of corresponding node.
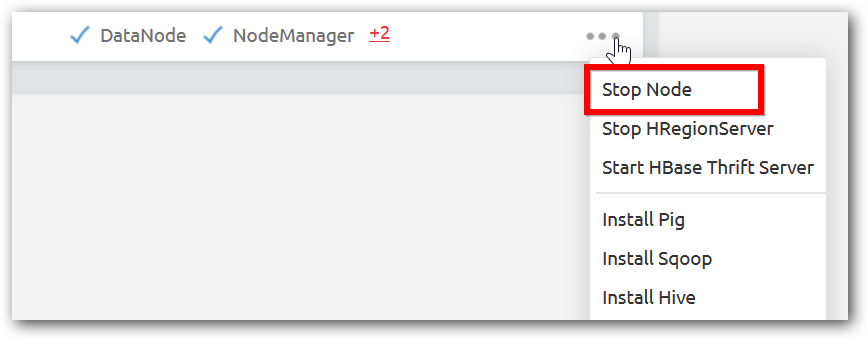
Step 2: After all services stopped in the node, remove option will be displayed. Select remove option as shown in below image.
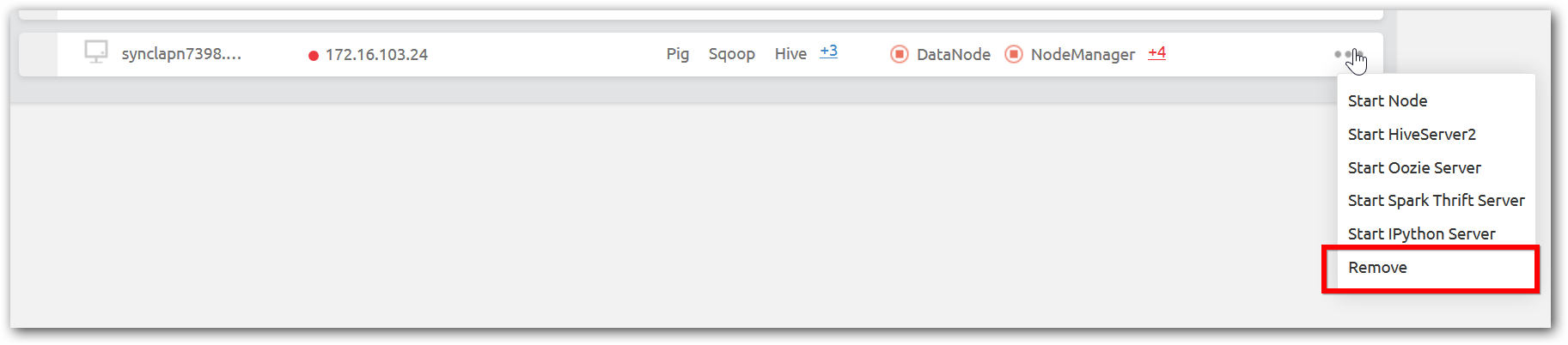
NOTE
Stop services manually and remove as mentioned above is not recommended way as data lose will occur in this procedure. So you have to decommission data nodes properly and remove to avoid data lose.
Add Journal Node into Hadoop Cluster
Journal node service will be running in first three nodes for name node Higher Availability. When the Data node which runs journal node service failed, the cluster is no longer in Higher Availability mode. In such situation to add a data node with journal node configuration, follow the below steps
Step 1:Install Big Data Agent in a machine which you want to add as journal node in cluster.
Step 2: Click Add Journal Node under Manage nodes menu in Management page of corresponding cluster.
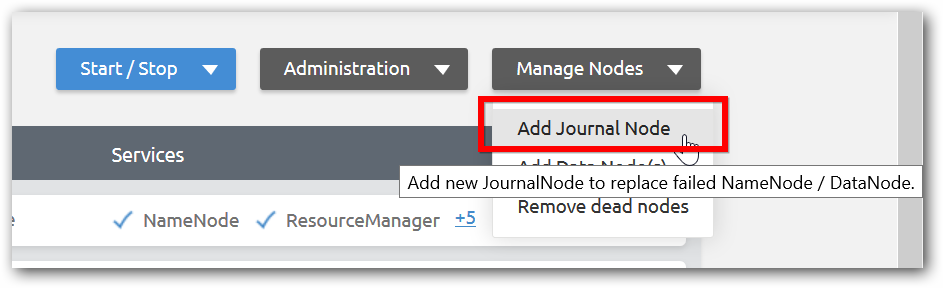
Step 3:Enter the IP address or host name of the machine, select the node type as Data Node (Journal Node) and click done.
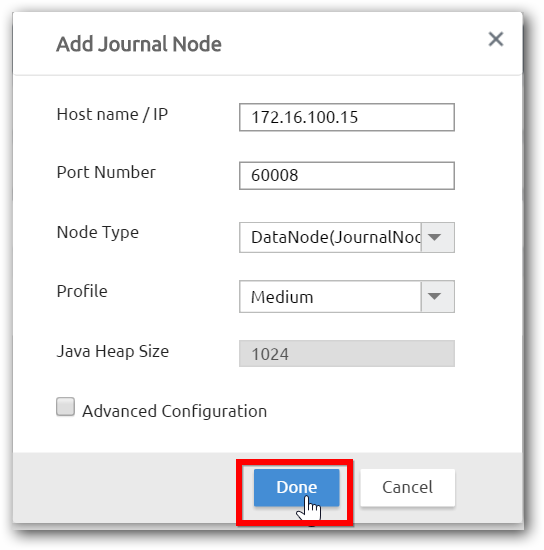
NOTE
Adding the journal node will restart the Hadoop cluster.
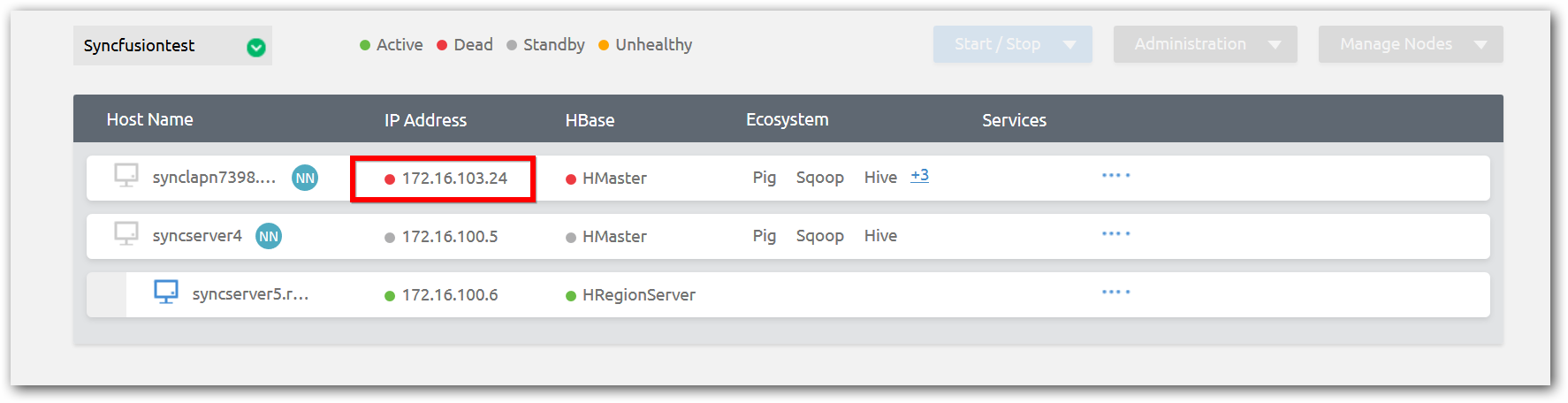
Add Name Node
When active Name node fails, standby Name node becomes Active Name node. We can add the new standby name node into the cluster to maintain Name node Higher Availability.
Step 1:Install the installer Agent in a machine which you want to add as standby Name node.
Step 2: Click Add Journal Node under Manage nodes menu from management page of corresponding cluster.
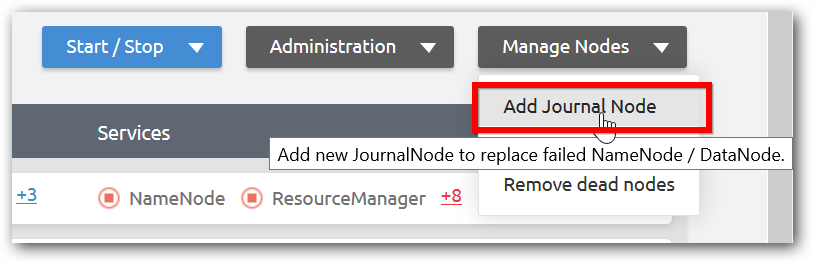
Step 3: Enter IP address of host name of the machine, select the node type as Name Node and click done.
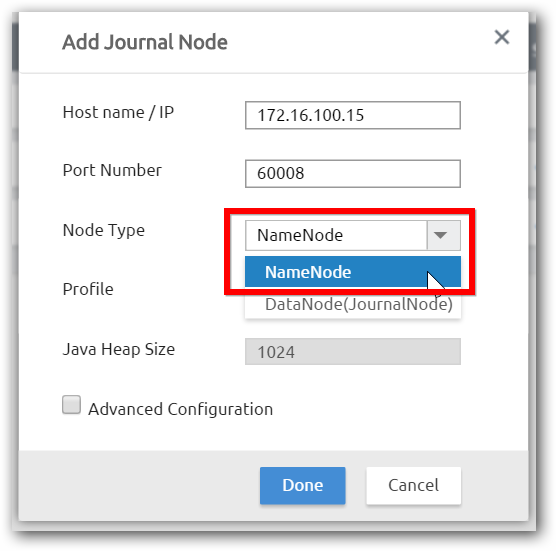
Step 4: Cluster Manager configured the Hadoop cluster with additional name node and starts the services of Hadoop cluster.
NOTE
Adding the journal node will restart the Hadoop cluster.
Add Data Node or Journal Node in Linux Secure Cluster
To add DataNode or JournalNode to the Kerberos enabled secure cluster formed using the cluster manager that is installed in a Linux machine, execute setspn command in Active Directory machine by following the given details.
NOTE
This manual command execution is required only in case the secure cluster is created with the Cluster Manager installed in the Linux machines. For other clusters and Cluster Manager in windows, this manual step is not required.
While adding data nodes to the secure cluster via Linux Cluster Manager,
Generate command for each data node you are adding by replacing the hostname and execute the same in the Active Directory machine.
setspn -s HTTP/[HostName] web_[OUName]
While adding journal node to the secure cluster via Linux Cluster Manager,
Generate the commands for the journal node you are adding by replacing the hostname.
Step 1: Remove setspn, if already added for the host.
setspn -d HTTP/[HostName] web_[OUName]
Step 2: Execute setspn command for the host.
setspn -s HTTP/[HostName] web_[OUName]
NOTE
OUName - Organization Unit name in Active Directory.
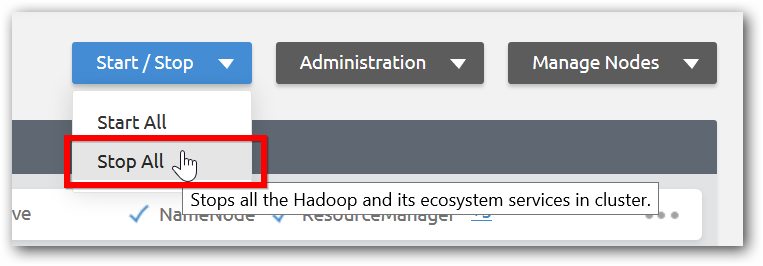
Manage Hadoop Services
To stop or start all Hadoop services use Services dropdown menu.
Ecosystem
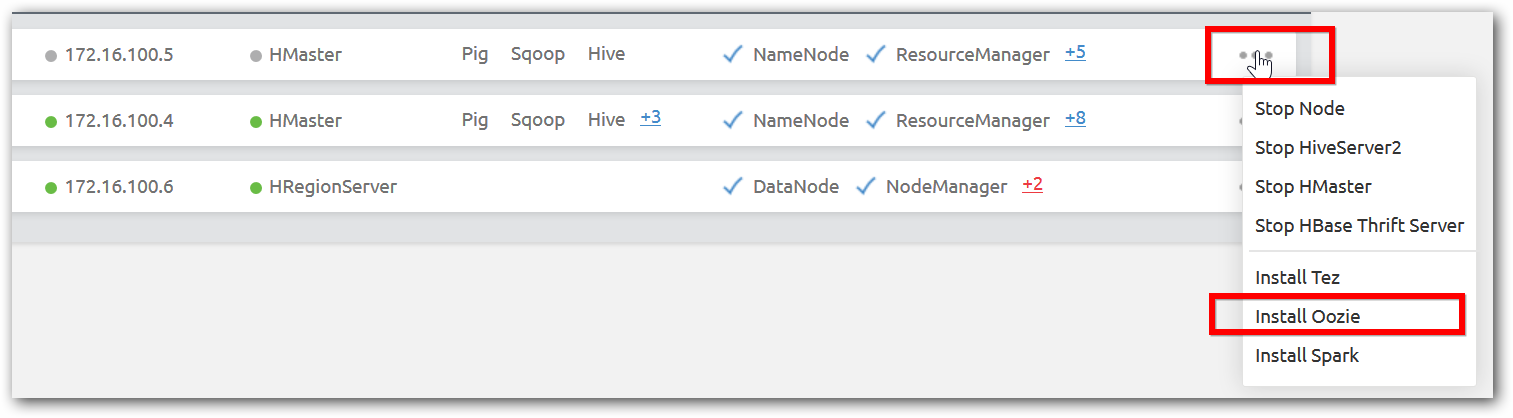
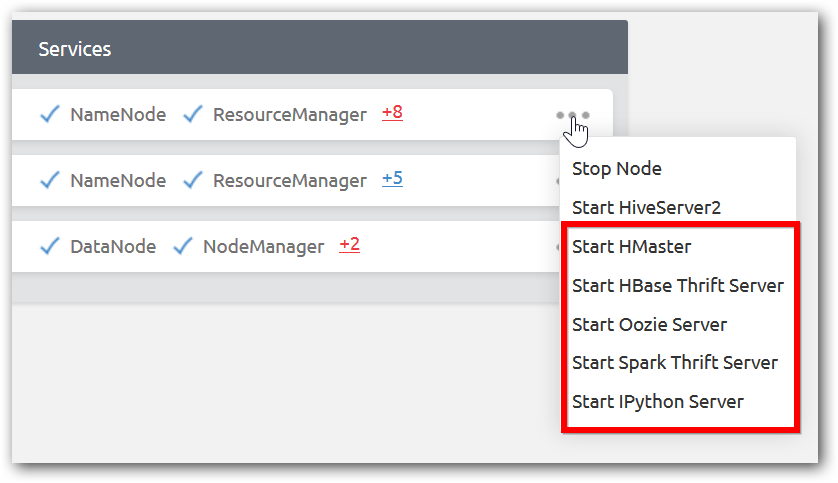
By default all ecosystem and supporting services such Sqoop, Pig, Hive, Spark, HBase, IPython and Oozie are available in name nodes. Hiveserver2, Oozie Server, HBase Thrift Server, IPython and Spark Thrift Server are running in Name nodes by default. To add and manage ecosystem in other nodes, use action menu in each node as shown in below image.
Add Existing Cluster
A cluster that has been already created can be managed Managing Existing Cluster option in Cluster Manager home page.
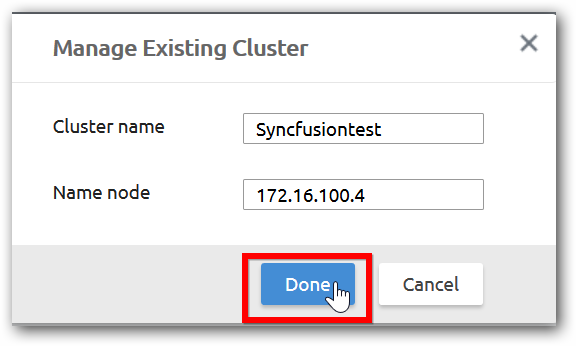
Click the Managing Existing Cluster option and enter a user defined name and a Name node IP or host name and click done.
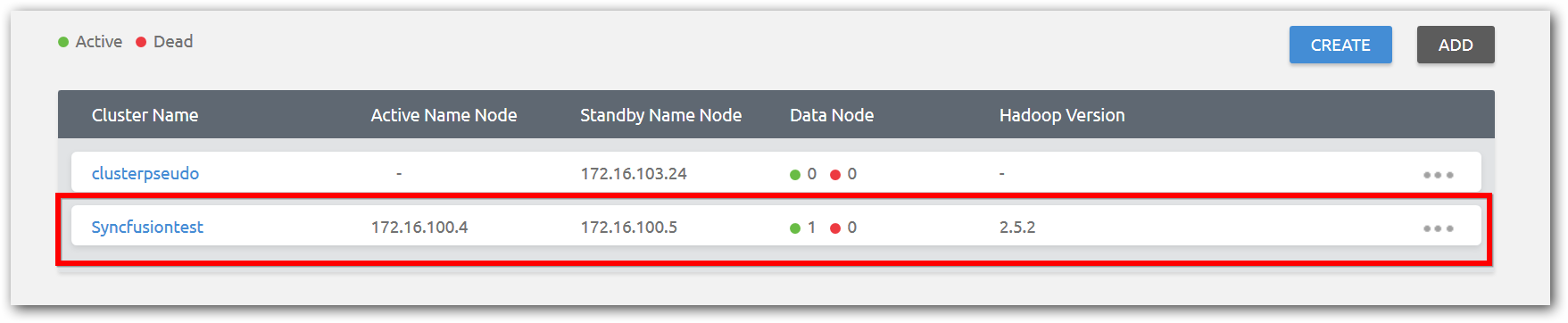
After successful validation of the Name node, a cluster entry is added to manage the cluster.
Log Aggregation
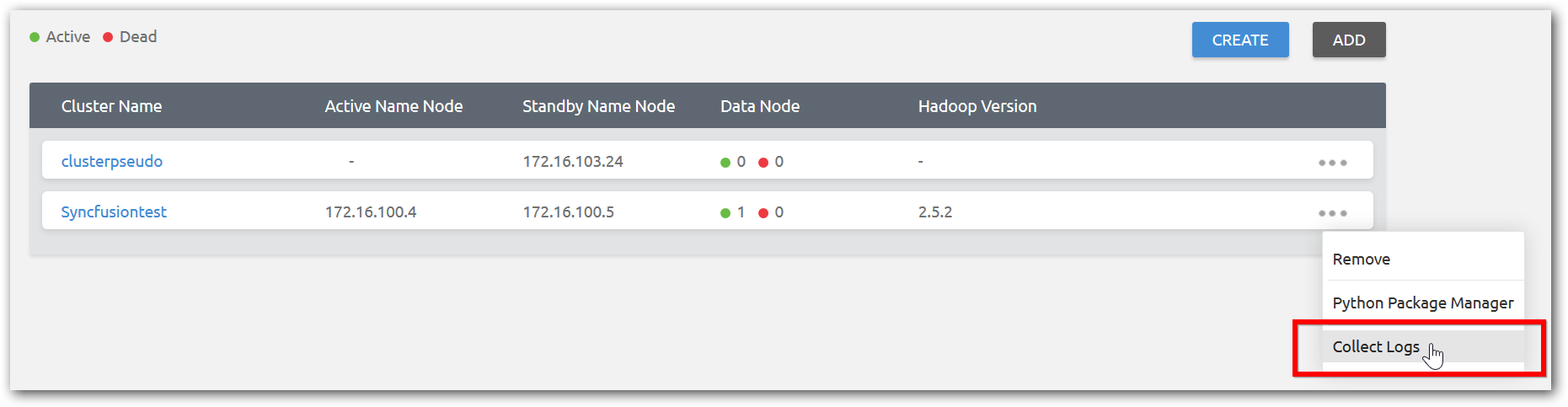
Collect logs option allow you to collect all type of application and Hadoop logs in a single click. It will be useful for issue reporting and internal log analysis.
Click Collect Logs from cluster manager home page. It will download logs from all cluster nodes as a single Zip file.
Backup and Restore
Apart from handling data loss and fault tolerance by replication factor in a cluster, you can take backup HDFS and HBase table data to another cluster or to Azure Blob storage. Cluster Manager provides restore option from backup data as well.
NOTE
Backup jobs will be scheduled using Oozie server that is running in the cluster.
Step 1: Click Back and Restore option under Option menu in management page.
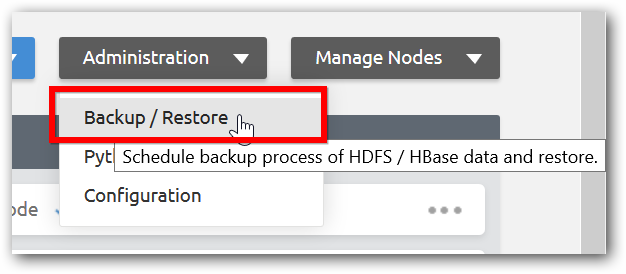
Step 2: Select HBase or HDFS backup as required and select backup type and provide required fields and click Done.
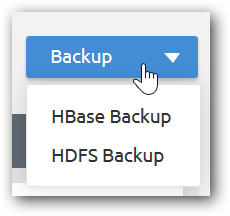
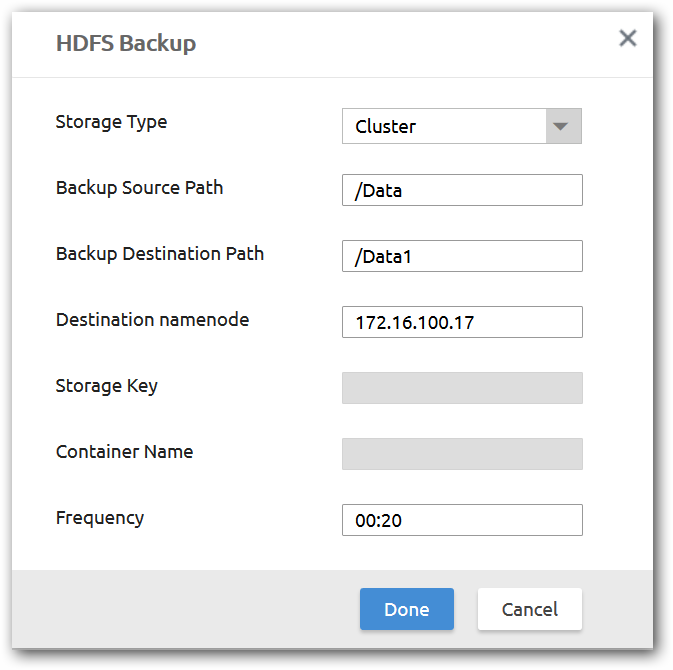
Based on provided details, an Oozie coordinator job will be submitted.

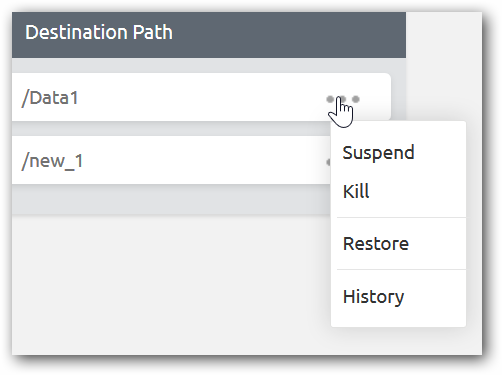
When the scheduled backup job is running, you can suspend, kill, perform restore operation and view history.
Python Package Manager
Python and IPython support for Spark, by default Python will be configured in each cluster nodes. You can manage the packages using Python package manager option.
Step 1: Click Python package manager option under Option menu in management page.
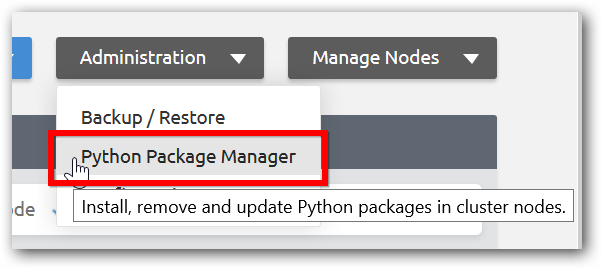
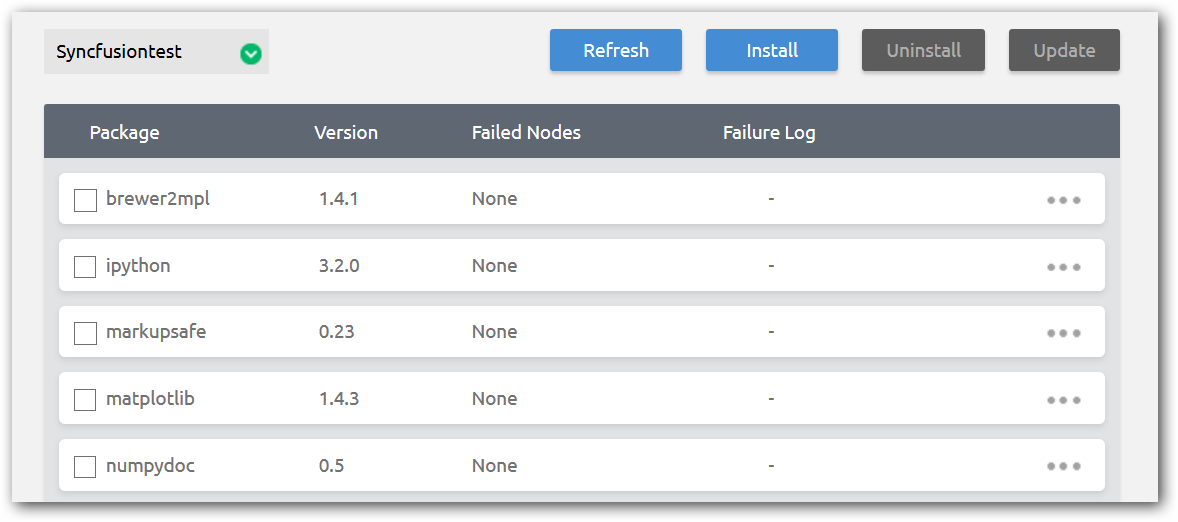
Step 2: In the page, you can install / uninstall and update individual or multiple packages at a time.
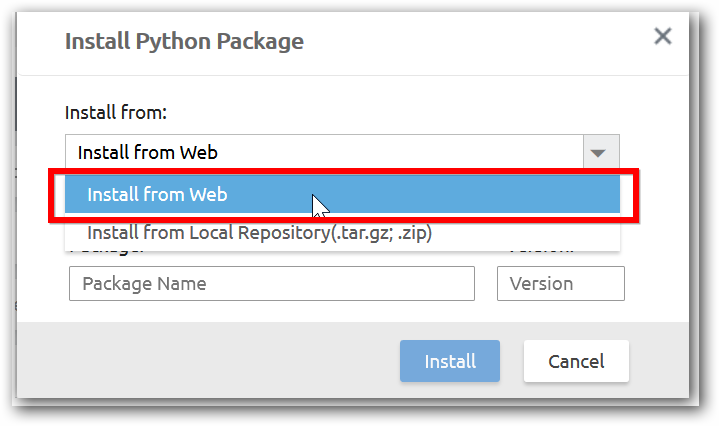
Step 3: In install package option, you can install it from web or local file.
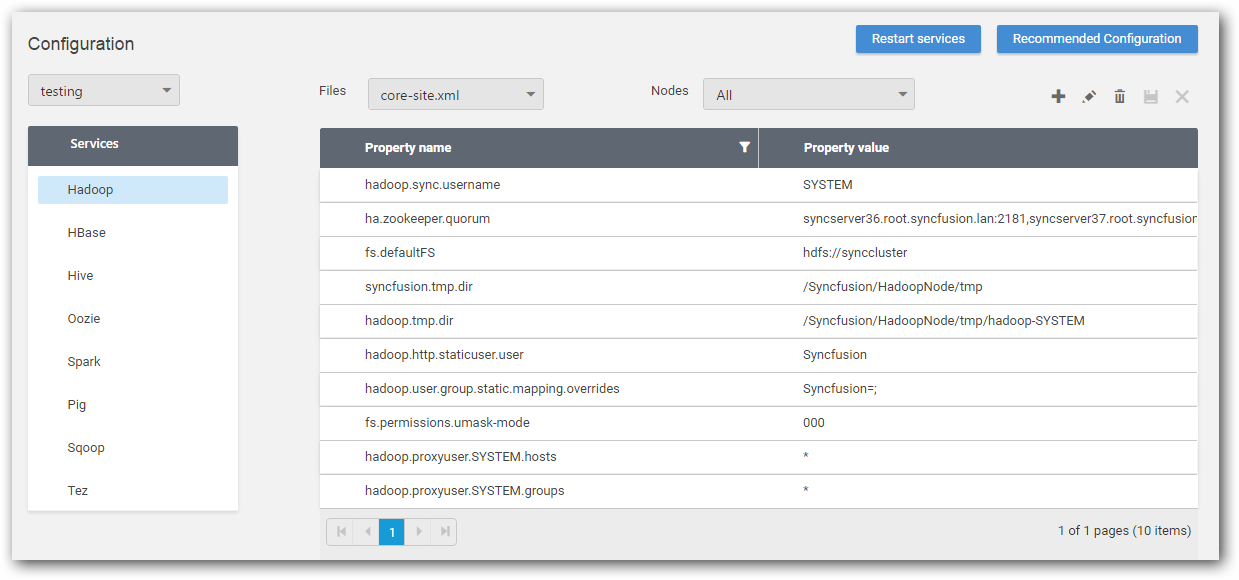
Customization of Hadoop and all Hadoop ecosystem configuration files
When creation of cluster, you would have advanced configuration to set Hadoop properties. Similarly you can edit Hadoop and all Hadoop ecosystem configuration files after cluster creation.
Step 1: Click Configuration under Administration options.
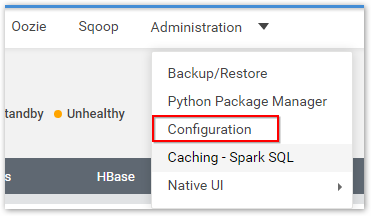
Step 2: Update existing or add new properties of Hadoop and ecosystem configuration files based on individual node or overall to the cluster, review and restart services.
NOTE
Some of configuration changes may require service restart.