Caching - Spark SQL
Spark supports pulling data sets into a cluster-wide in-memory cache. Spark SQL cache the data in optimized in-memory columnar format. One of the most important capabilities in Spark is caching a dataset in memory across operations. Caching computes and materializes an RDD in memory while keeping track of its lineage. The cache behavior depends on the available memory since it will load the whole dataset into cache memory using Spark SQL query.
Cache table
Click “Caching - Spark SQL” under “Administration” and click “cache table”.

Select database and table to perform cache operation and click “Cache”.

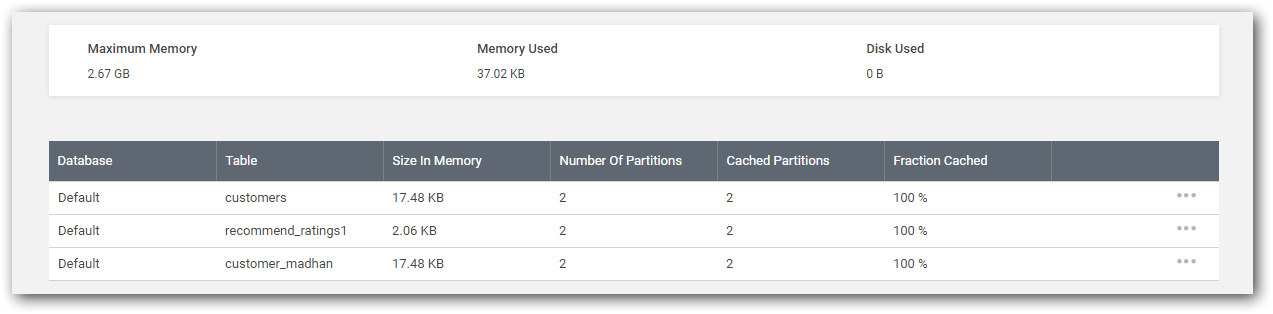
Cached tables and memory utilization details are listed in a grid as below.
You can also re-cache and un-cache existing cached tables as required.