Syncfusion Big Data Platform Overview
Syncfusion Big Data Studio is an integrated environment for working with Big Data. It ships along with a local pseudo-distributed Hadoop cluster that can be used for development purposes. The local cluster is installed by default with Syncfusion Big Data SDK setup installation and is managed by a local service manager. The local cluster runs on a single machine and simulates the operation of a complete cluster on a single machine. It is useful for development purposes. You can perform most work without being connected to a production cluster.
Syncfusion Big Data Studio can also connect to production instances of the Syncfusion Big Data platform. A production cluster runs on an actual set of machines and is configured and managed using the Syncfusion Big Data Cluster Manager.
Getting started
- To get started simply install the Syncfusion Big Data Studio application accepting defaults.
- Start the Big Data Platform Dashboard application.
- Click on the Service Manager button to launch the service manager application.
- Starting this application will automatically start the process to start the local Hadoop cluster. This may take a few minutes especially the first time around.
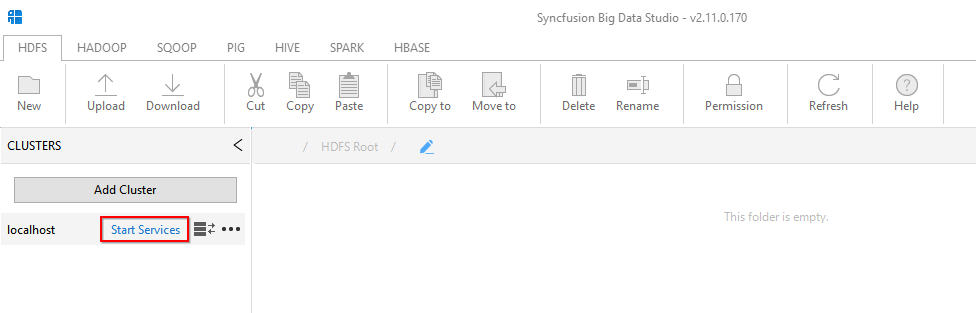
- Once the local cluster is running each service will have a green icon next to it. If there are issues initializing then a red icon is displayed against each service that did not initialize. In cases where you see an error please contact Syncfusion for further assistance.
- Please note that HBase and Spark Thrift services are not started by default in order to keep memory usage down. You can start these services also if you plan to work with them during this session.
- You can then start the Big Data Studio application.
- Once the application comes up you will be presented with an interface where you can add a cluster. In order to add the local cluster you can simply use localhost.
- The studio application will take a few seconds to connect. Once connected the view will automatically switch to display the HDFS filesystem on the local cluster.
- At this point you can navigate between tabs and access systems such as Hive, Pig, Sqoop and HBase.
- Navigating to the Spark tab for the first time may take a bit longer since the system starts Spark on demand due to Spark’s memory requirements being higher than for core Hadoop services.
- Several samples are provided with the product and can be easily submitted for processing from within the studio environment itself.
- With the Java and Scala samples a Gradle build file is provided along with a readme file that details steps that can be taken to build and submit samples directly using Gradle or by using an IDE such as IntelliJ or Eclipse.
- For C# samples Visual Studio project files are provided.
Working with the local install of Hadoop directly from the command shell or from PowerShell
We provide shortcuts for this purpose directly from the installed dashboard. These links start the appropriate shell along with the right environment settings.
IMPORTANT
Several samples use an environment variable named “SYNCBDP_HOME”. If working with an IDE please ensure that this variable is set to the root of the installation directory. This is typically “C:\Syncfusion\BigData[version]\BigDataSDK”. You do not need to set this value when working within the big data studio or from shells initialized by Syncfusion installed shortcuts.
Installing the Syncfusion Big Data Studio
Software Requirements
- Windows 7, Windows Server 2008 R2 or later (Only 64 bit version is supported)
- .NET Framework 4.5 or later
Hardware Requirements
- RAM - 8 GB or higher.
- Hard disk – 100 GB or higher
Steps
- Download Syncfusion Big Data Studio from here
- Walk-through the installer steps
- For most installations the defaults will work
- Start Big Data Studio from the installed Syncfusion Big Data Platform Dashboard.
NOTE
By default, Big Data studio is already configured with localhost. In order to work with pseudo node cluster,
we should start the local Hadoop services from Big Data Studio by clicking Start Service link button or using local service manager.
Local service manager
Add New Cluster
To add a new cluster click the “Add Cluster” button in the Clusters panel.
It will display the Add cluster window.
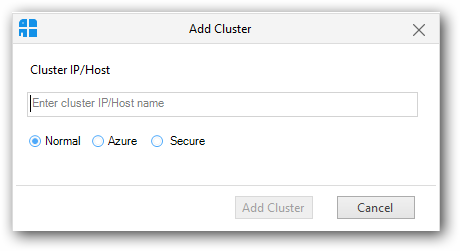
NOTE
Cluster should be created by Syncfusion Big data Cluster manager.
Add Normal Cluster
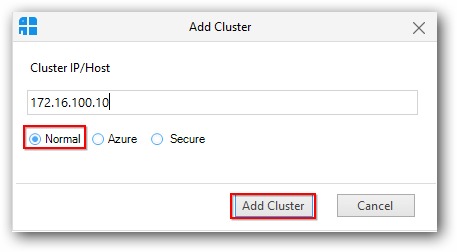
To add a normal cluster(Windows/Linux),select the “Normal” radio button and provide active name node IP address / host name in the text box and click “Add Cluster” button.
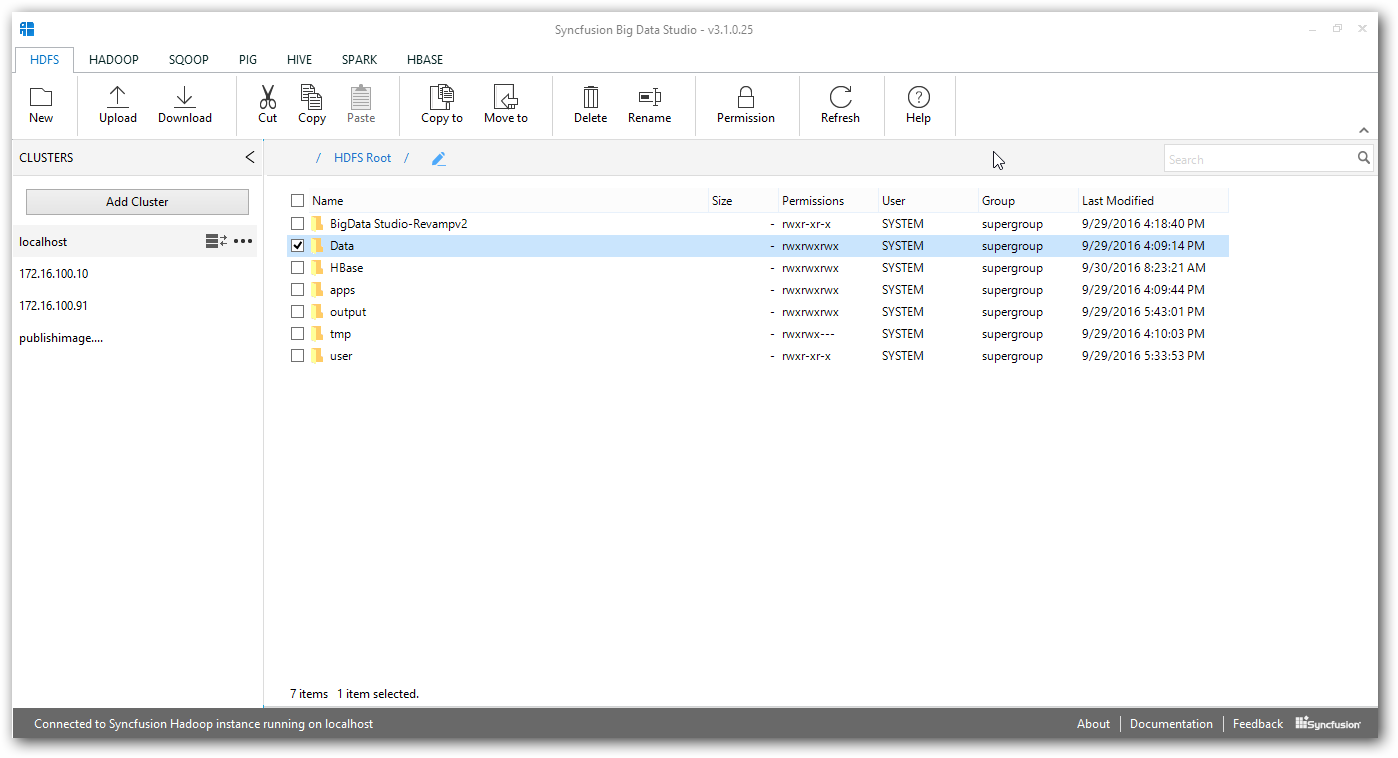
After connecting with the cluster, Big Data studio connect with the cluster and displays the HDFS table.
Add Secure Cluster
To add a secure cluster, click the “Add Cluster” button in the Clusters panel. It will display an Add cluster window.
In that window, select the “Secure” radio button.
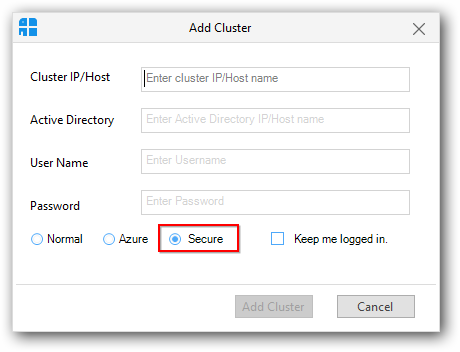
As like adding normal cluster, you need to provide active name node IP / host name, in addition enter Active Directory server host name or IP address and its credentials.
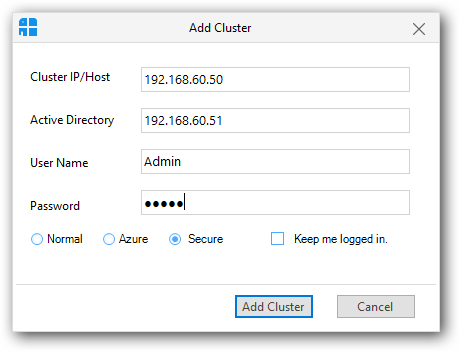
Then click “Add Cluster” button to add secure cluster.
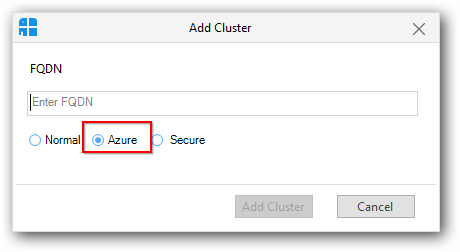
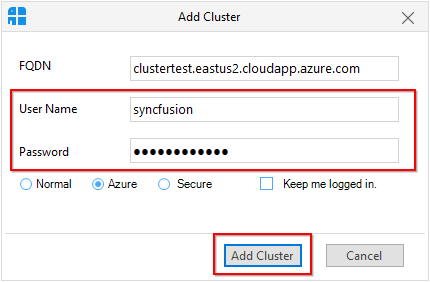
Add Azure Cluster
To add an Azure cluster (Basic authentication, Kerberos and Sandbox), click the “Add Cluster” button in the Clusters panel. It will display an Add cluster window.
In that window, select the “Azure” radio button.
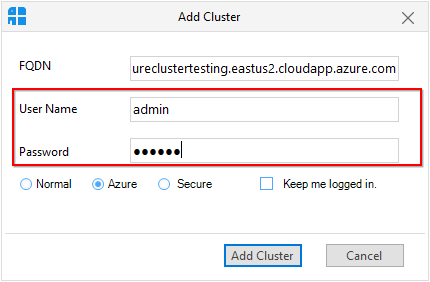
To add an Azure cluster, you need to provide FQDN and cluster Manager credentials and then click “Add Cluster” button.
You can get FQDN of an Azure cluster from “View Details” page in cluster manager as shown in below screenshot.
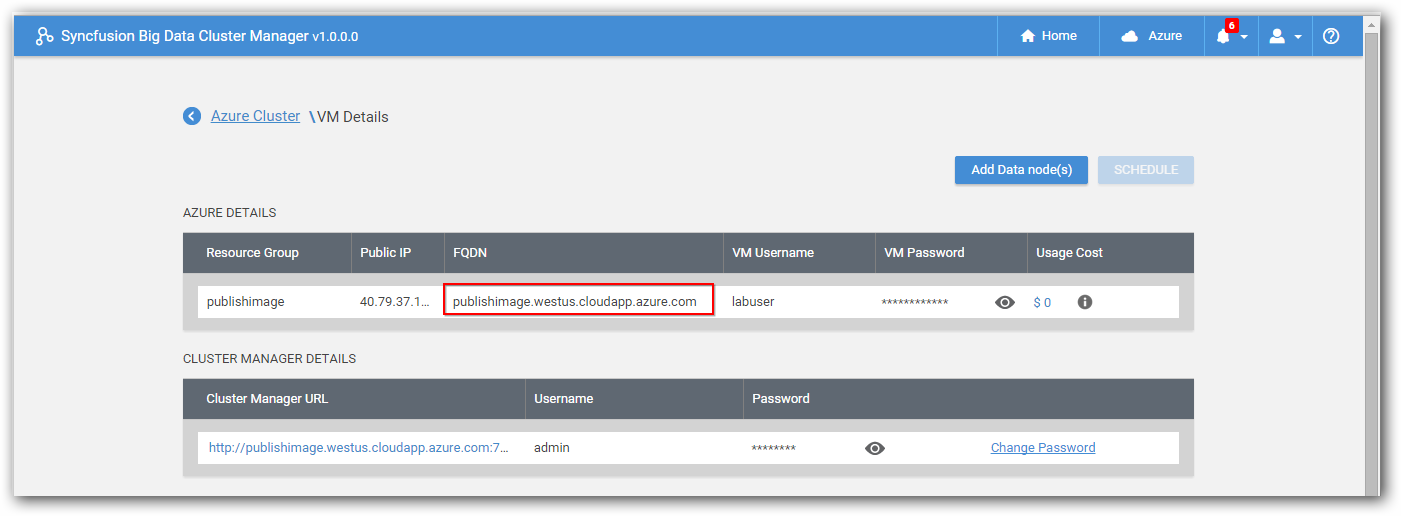
Similarly, to add Kerberos enabled Azure cluster, provide Active Directory credentials of Azure cluster instead of Cluster Manger credentials and then click “Add Cluster” button.
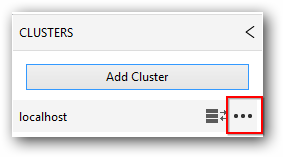
Steps to view Cluster details:
- Click on the connected cluster, then click the option button in it.
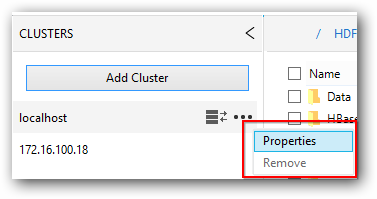
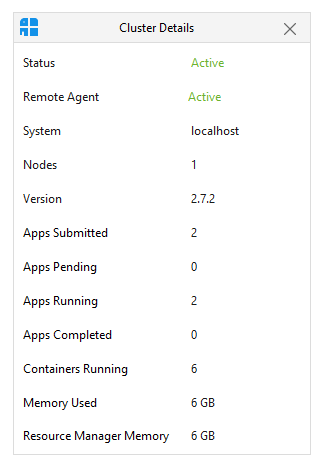
- Click the “Properties” option in it. It will displays the cluster details in a separate window.
Switching between the cluster
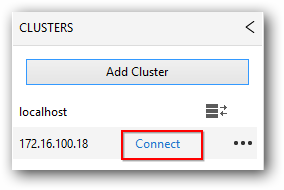
To switch between the cluster, just select the required cluster from the list displayed in the clusters tab and click “Connect”.
Remove Cluster
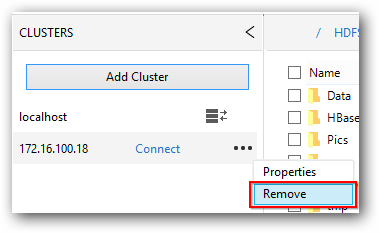
To remove cluster from the list maintained in clusters panel, just select the cluster and click option button and select “Remove”.
Features
Big data studio provides following features.
- Interactively work with the Hadoop distributed file system, HDFS.
- HDFS file viewer is available to view the text contents of files in HDFS.
- Prepare and manage SQOOP jobs.
- Interactive shells available for Hadoop, Pig, Hive, HBase and Spark (Scala and python)
- Manage Hadoop commands and save them for later use.
- Run Pig, Hive, Spark (Scala, Python and Spark SQL) and HBase scripts and save them for later use.
- Tez mode support is available for Pig and Hive.
- View results as grid / plain text in Pig, Hive and HBase module.
- IPython is integrated and optimized to work with PySpark
- Spark SQL is integrated and optimized to work with Spark Thrift server.