Description and usage of PutParquet:
Reads records from an incoming FlowFile using the provided Record Reader and writes those records to a Parquet file. The schema for the Parquet file must be provided in the processor properties. This processor will first write a temporary dot file, and after successfully writing every record to the dot file, it will rename the dot file to its final name. If the dot file cannot be renamed, the rename operation will be attempted up to ten times, and if still not successful, the dot file will be deleted, and the flow file will be routed to failure. If any error occurs while reading records from the input or writing records to the output, the entire dot file will be removed, and the flow file will be routed to failure or retry, depending on the error.
Tags:
put, Parquet, Hadoop, HDFS, filesystem, restricted
Properties:
In the following list, the names of required properties appear in bold. Any other properties (not in bold) are considered as optional. The table also provides information on default values and whether a property supports the Expression Language Guide.
|
Name |
Default Value |
Allowable Values |
Description |
| Hadoop Configuration Resources | A file or comma-separated list of files that contains the Hadoop file system configuration. Without this, Hadoop will search the classpath for a 'core-site.xml' and 'hdfs-site.xml' file or will revert to a default configuration. | ||
| Kerberos Principal | Kerberos principal to authenticate as. Requires nifi.kerberos.krb5.file to be set in your nifi.properties | ||
| Kerberos Keytab | Kerberos keytab associated with the principal. Requires nifi.kerberos.krb5.file to be set in your nifi.properties | ||
| Kerberos Relogin Period | 4 hours | Period of time which should pass before attempting a Kerberos relogin | |
| Additional Classpath Resources | A comma-separated list of paths to files and/or directories that will be added to the classpath. When a directory is specified, all files within the directory are added to the classpath, but further sub-directories are not included. | ||
|
Record Reader |
Controller Service API: RecordReaderFactory Implementations: JsonPathReader CSVReader ScriptedReader AvroReader GrokReader JsonTreeReader |
The service for reading records from incoming flow files. | |
|
Directory |
The parent directory to which files should be written. Will be created if it doesn't exist. Supports Expression Language: true |
||
|
Schema Access Strategy |
schema-name |
|
Specifies how to obtain the schema to be used for writing the data. |
| Schema Registry |
Controller Service API: SchemaRegistry Implementations: AvroSchemaRegistry HortonworksSchemaRegistry |
Specifies the Controller Service to use for the Schema Registry | |
| Schema Name | ${schema.name} |
Specifies the name of the schema to lookup in the Schema Registry property Supports Expression Language: true |
|
| Schema Text | ${avro.schema} |
The text of an Avro-formatted Schema Supports Expression Language: true |
|
|
Compression Type |
UNCOMPRESSED |
|
The type of compression for the file being written. |
|
Overwrite Files |
false |
|
Whether or not to overwrite existing files with the same name in the same directory. When set to false, flow files will be routed to failure if a file exists with the same name in the same directory. |
| Permissions umask | A umask is represented as an octal number that determines the permissions of files written to HDFS. This overrides the Hadoop Configuration dfs.umaskmode. | ||
| Remote Group | The group of the HDFS file is changed to the specified value after it is written, but only if NiFi is running as a user with HDFS superuser privileges. | ||
| Remote Owner | The ownership of the HDFS file is changed to the specified value after it is written, but only if NiFi is running as a user with HDFS superuser privileges to change ownership. | ||
| Row Group Size |
The row group size used by the Parquet writer. The value is specified in the format of <Data Size> <Data Unit> where Data Unit is one of B, KB, MB, GB, TB. Supports Expression Language: true |
||
| Page Size |
The page size used by the Parquet writer. The value is specified in the format of <Data Size> <Data Unit> where Data Unit is one of B, KB, MB, GB, TB. Supports Expression Language: true |
||
| Dictionary Page Size |
The dictionary page size used by the Parquet writer. The value is specified in the format of <Data Size> <Data Unit> where Data Unit is one of B, KB, MB, GB, TB. Supports Expression Language: true |
||
| Max Padding Size |
The maximum amount of padding that will be used to align row groups with blocks in the underlying filesystem. If the underlying filesystem is not a block filesystem like HDFS, this has no effect. The value is specified in the format of <Data Size> <Data Unit> where Data Unit is one of B, KB, MB, GB, TB. Supports Expression Language: true |
||
| Enable Dictionary Encoding |
|
Specifies whether dictionary encoding should be enabled for the Parquet writer | |
| Enable Validation |
|
Specifies whether validation should be enabled for the Parquet writer | |
| Writer Version |
|
Specifies the version used by Parquet writer | |
| Remove CRC Files | false |
|
Specifies whether the corresponding CRC file should be deleted upon successfully writing a Parquet file |

Relationships:
|
Name |
Description |
| retry | Flow Files that could not be processed due to issues that can be retried are transferred to this relationship |
| success | Flow Files that have been successfully processed are transferred to this relationship |
| failure | Flow Files that could not be processed due to issue that cannot be retried are transferred to this relationship |
Reads Attributes:
|
Name |
Description |
| filename | The name of the file to write comes from the value of this attribute. |
Writes Attributes:
|
Name |
Description |
| filename | The name of the file is stored in this attribute. |
| absolute.hdfs.path | The absolute path to the file is stored in this attribute. |
| record.count | The number of records written to the Parquet file |
State management:
This component does not store state.
Restricted:
Provides operator the ability to write to any file that NiFi has access to in HDFS or the local filesystem.
Input requirement:
This component requires an incoming relationship.
How to configure
Step 1: Drag and drop the PutParquet processor to canvas.
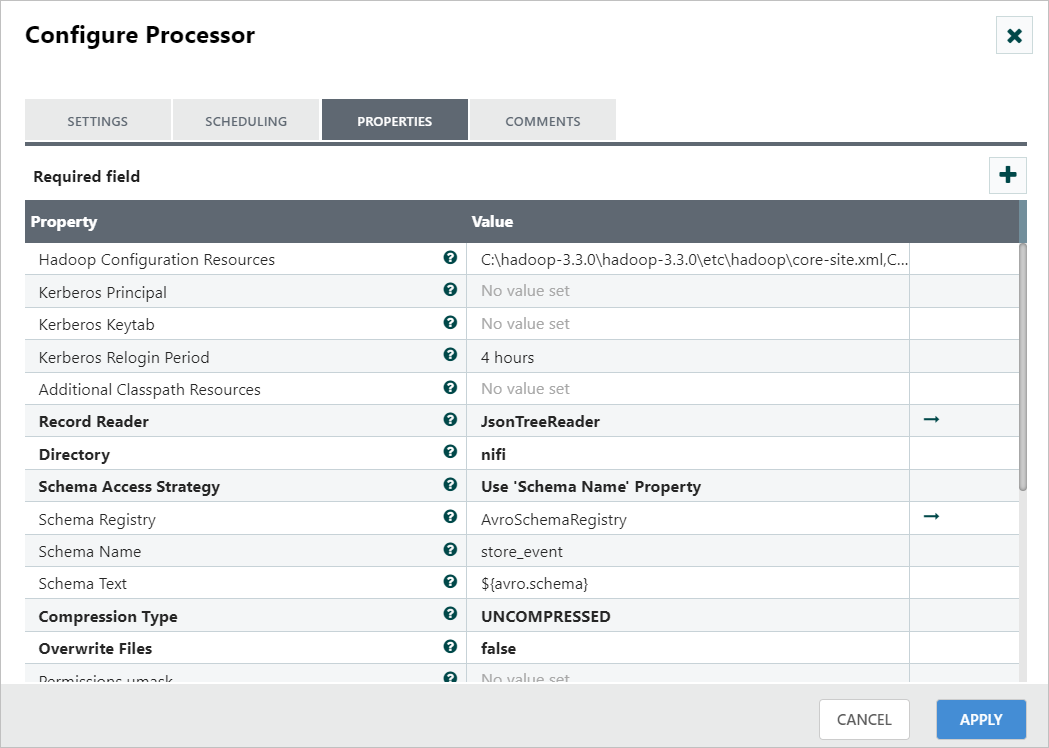
Step 2: Double-click the processor to configure, and the configuration dialog will be opened as follows.
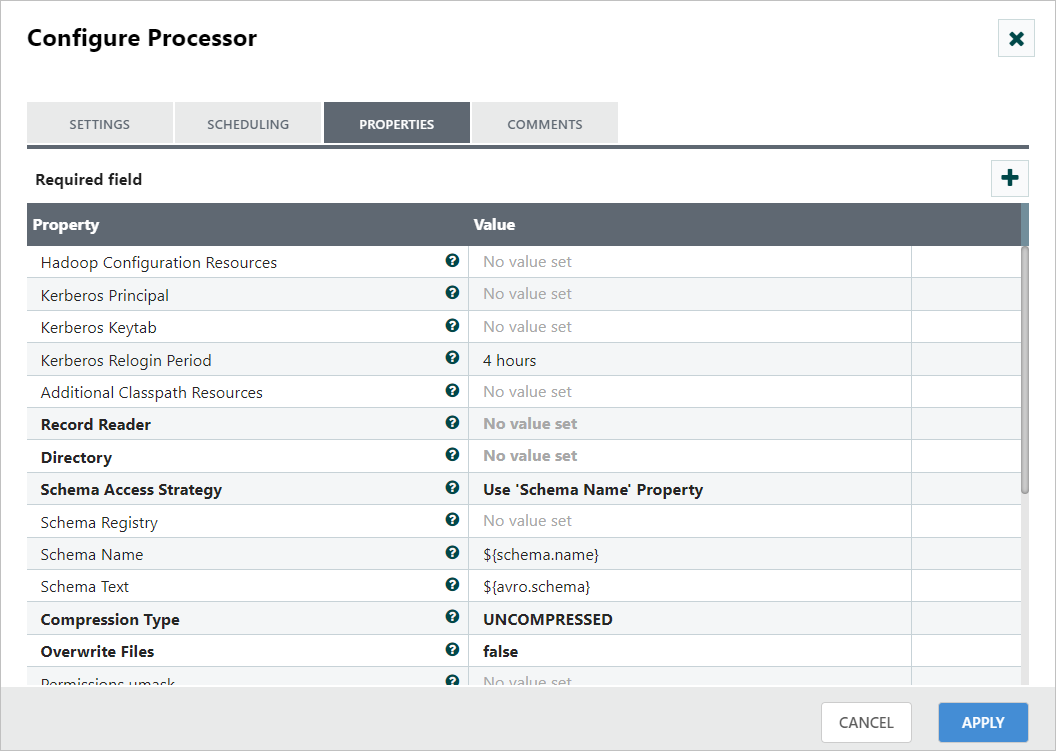
Step 3: Check the usage of each property and update those values.
Properties and usage
Hadoop Configuration Resources: A local path for core-site.xml and hdfs-site.xml files from our Hadoop cluster.
RecordReader: A JSONTreeReader that can be utilized to read the source data, convert it to a record format, and store it in memory. This record reader should be configured with the same schema and schema access strategy as the PutParquet.
Directory: An HDFS directory where Parquet files will be written.
Schema Access Strategy: The schema for written data can be obtained using the Schema Registry for a more governed solution or by using the Schema Text property for simplicity.
Schema text: The Avro Schema that you defined in the previous section.
Other parameters: This processor has several parameters to help tune the Parquet conversion. Use those parameters if you needed.
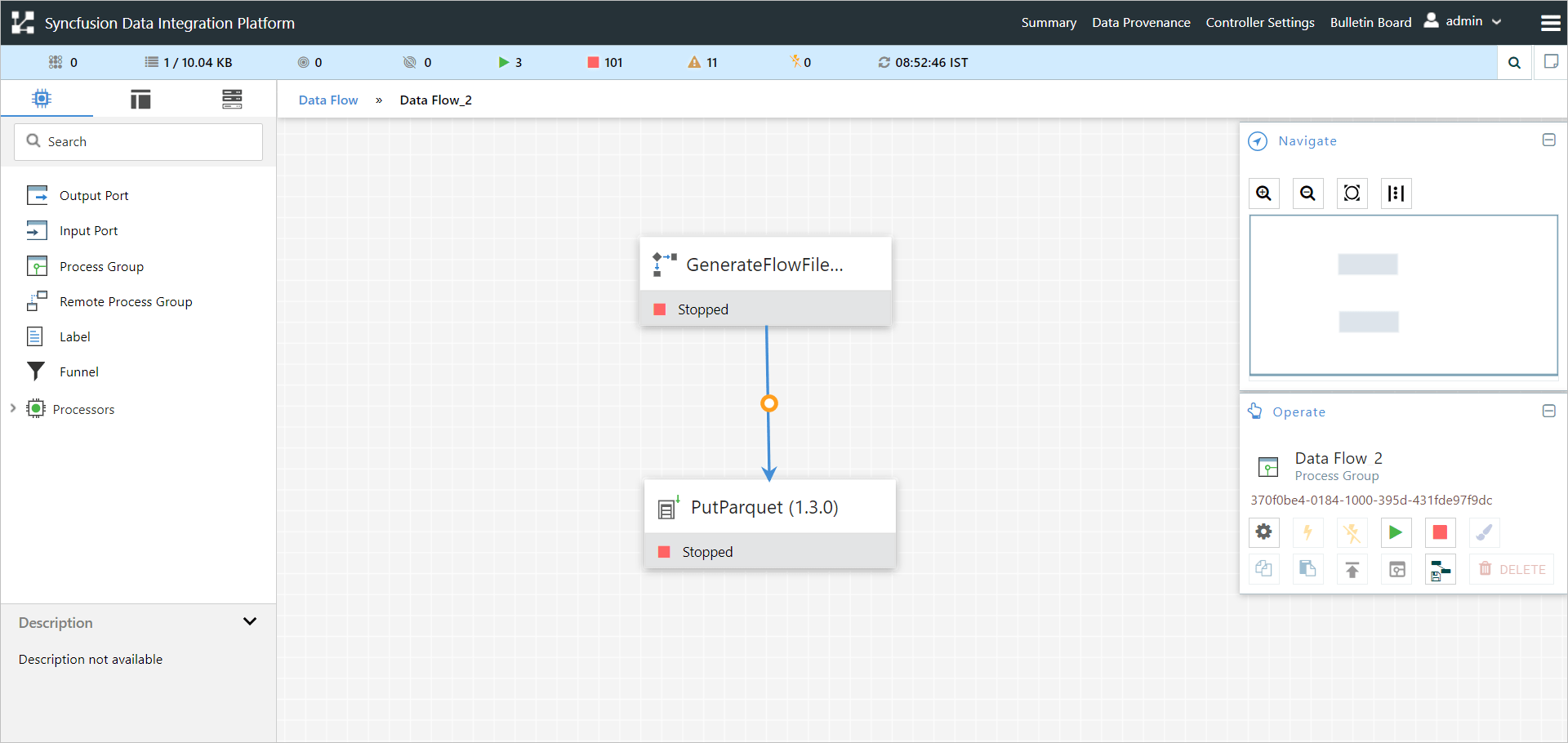
Sample Workflow:
The PutParquet processor is used to convert data from different formats such as Avro, CSV, or JSON to Parquet. This sample workflow demonstrates how to use the PutParquet processor to convert data from JSON to Parquet format within the data integration platform.
List of processors used in this sample:
|
Processor |
Comments |
| GenerateFlowFile | Reads the full body of each page of documents into memory and writes the queried Flow Files for transfer |
| PutParquet | Writes parquet data directly into HDFS |
Workflow screenshot
Input data
sample JSON data source structure:
{
"created_at" : "Tue Oct 11 23:47:11 CEST 2023",
"product_id" : "23",
"product_type" : "Normal",
"value" : "1507664832649",
"transaction_id" : "6594277248900858122"
}
sample JSON data source structure:
{
"type" : "record",
"namespace" : "store_event",
"name" : "nifi",
"fields" : [
{ "name" : "created_at" , "type" : "string" },
{ "name" : "product_id" , "type" : "int" },
{ "name" : "product_type" , "type" : "string" },
{ "name" : "value" , "type" : "int" },
{ "name" : "transaction_id" , "type" : "string" }
]
}
Step 1: Configure GenerateFlowFile processor
Drag and drop the GenerateFlowFile processor to the canvas area. Configure with Json Data source and required properties in the configuration dialog, as shown in the following screenshots.
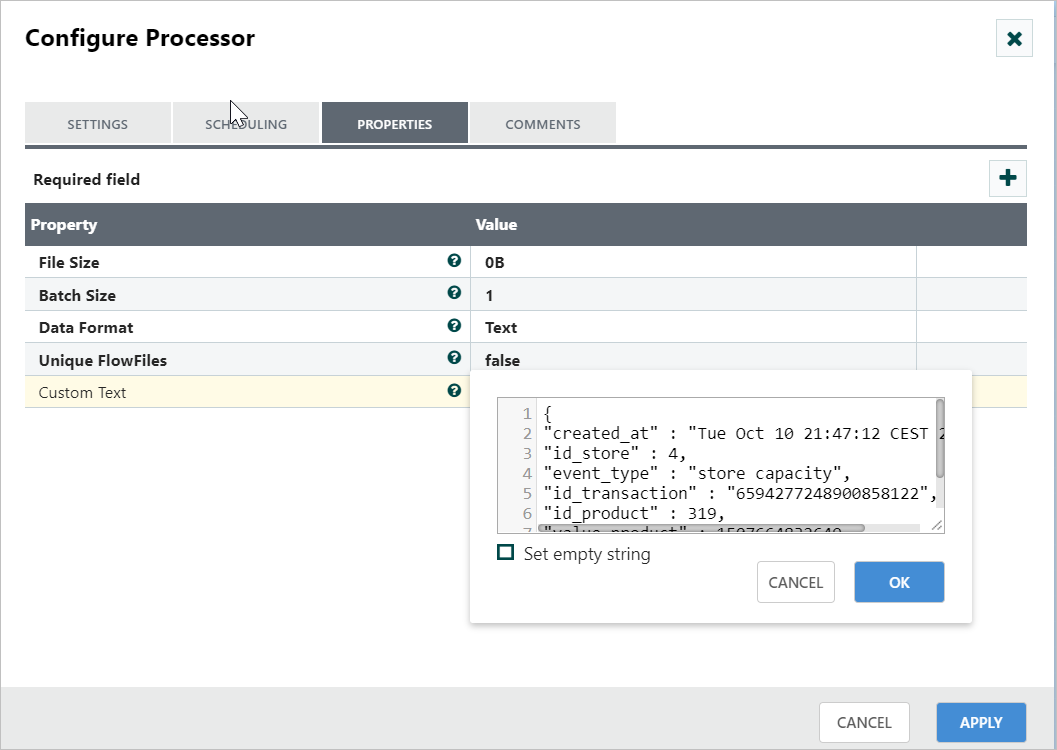
Step 2: Configure the PutParquet processor
Drag and drop the PutParquet processor to the canvas area. PutParquet is a special record-based processor because of the specificities of the Parquet format. Since Parquet’s API is based on the Hadoop Path object and not InputStreams/OutputStreams, NiFi does not generate a Parquet flow file directly. Instead, NiFi takes data in record format and writes it in Parquet on an HDFS cluster. Configure with Avro schema and required properties in the configuration dialog, as shown in the following screenshot. Also, make a connection between GenerateFlowFile and PutParquet with a ‘Success’ relationship.
Step 3: Starting the workflow
Once all processors are configured, start the workflow.
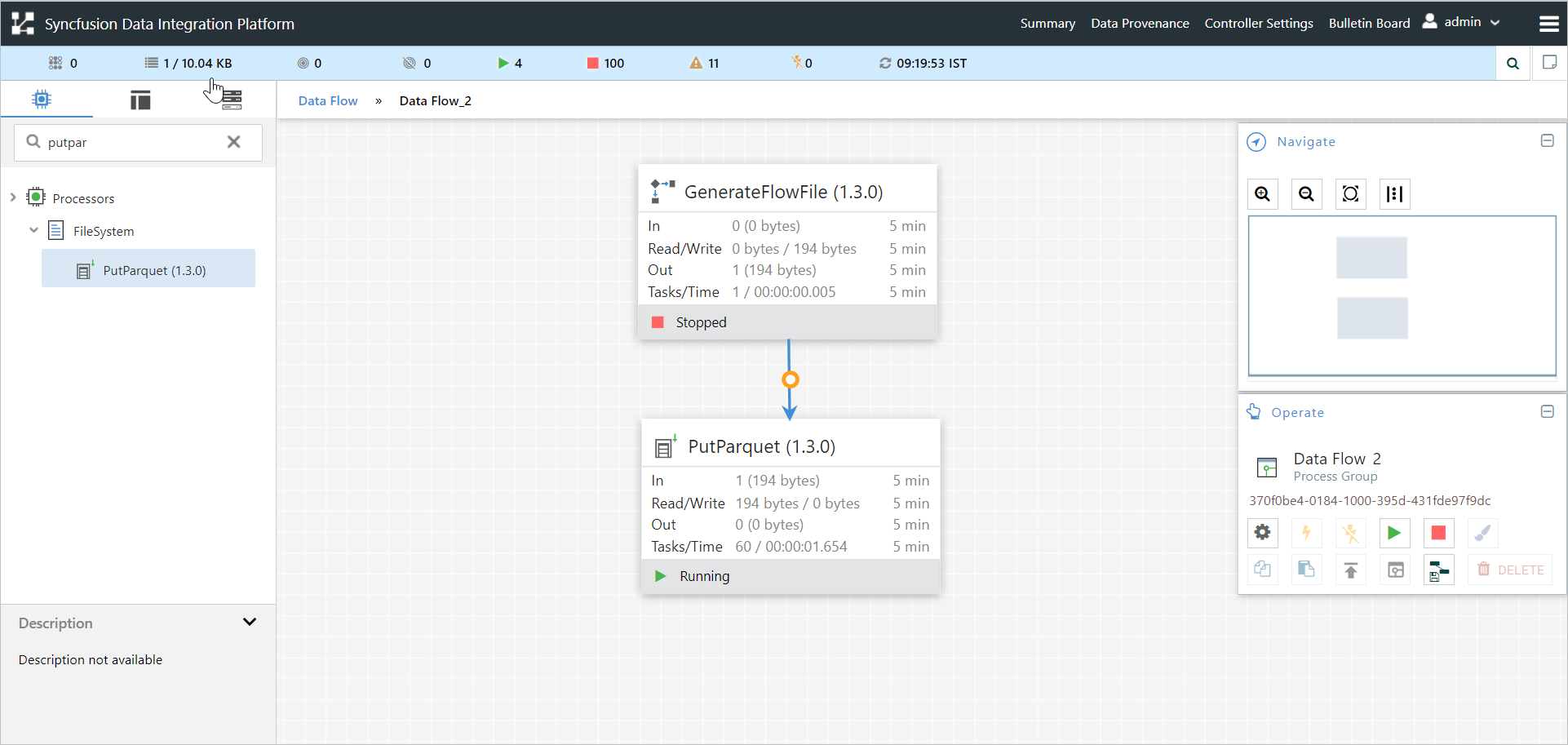
You can see the converted Parquet file in the HDFS cluster.