Description and usage of PutHBaseJSON processor:
Adds rows to HBase based on the contents of incoming JSON documents. Each FlowFile must contain a single UTF-8 encoded JSON document, and any FlowFiles where the root element is not a single document will be routed to failure. Each JSON field name and value will become a column qualifier and value of the HBase row. Any fields with a null value will be skipped, and fields with a complex value will be handled according to the Complex Field Strategy. The row id can be specified either directly on the processor through the Row Identifier property, or can be extracted from the JSON document by specifying the Row Identifier Field Name property. This processor will hold the contents of all FlowFiles for the given batch in memory at one time.
Tags:
hadoop, hbase, put, json
Properties:
In the list below, the names of required properties appear in bold. Any other properties (not in bold) are considered optional. The table also indicates any default values, and whether a property supports the Expression Language Guide.
| Name | Default Value | Allowable Values | Description |
| HBase Client Service |
Controller Service API: HBaseClientService Implementation: HBase_1_1_2_ClientService |
Specifies the Controller Service to use for accessing HBase. | |
| Table Name |
The name of the HBase Table to put data into Supports Expression Language: true |
||
| Row Identifier |
Specifies the Row ID to use when inserting data into HBase Supports Expression Language: true |
||
| Row Identifier Field Name |
Specifies the name of a JSON element whose value should be used as the row id for the given JSON document. Supports Expression Language: true |
||
| Column Family |
The Column Family to use when inserting data into HBase Supports Expression Language: true |
||
| Batch Size | 25 | The maximum number of FlowFiles to process in a single execution. The FlowFiles will be grouped by table, and a single Put per table will be performed. | |
| Complex Field Strategy | Text |
* Fail  * Warn * Ignore * Text
|
Indicates how to handle complex fields, i.e. fields that do not have a single text value. |
Relationships:
| Name | Description |
| failure | A FlowFile is routed to this relationship if it cannot be sent to HBase |
| success | A FlowFile is routed to this relationship after it has been successfully stored in HBase |
Reads Attributes:
None specified.
Writes Attributes:
None specified.
How to configure?
This sample explains how to insert the JSON records into an HBase table.
Overview:
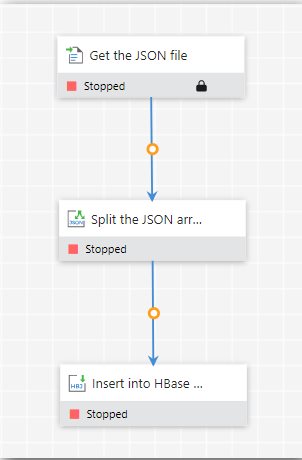
Input JSON file:
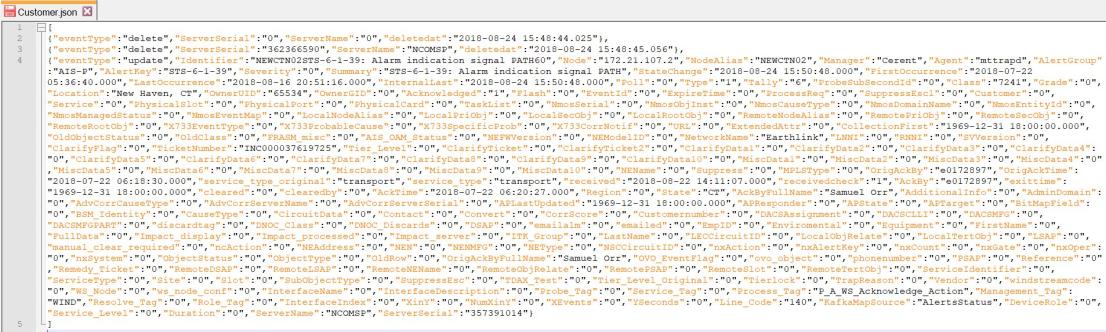
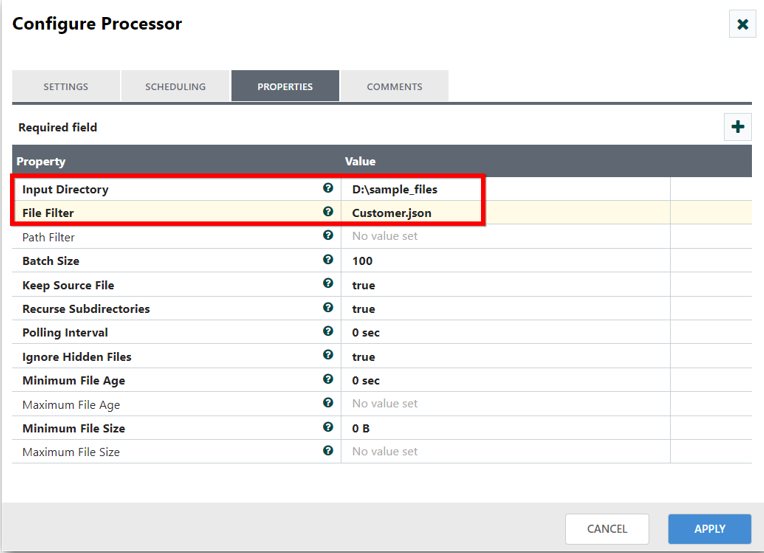
Step 1: Get the file content
Drag and drop the GetFile processor and specify the Input Directory and File Filter to fetch the JSON file.
Step 2: Split the JSON array
Drag and drop the SplitJson processor and specify the JSON path to split the JSON array. The SplitJson processor traverses inside the specified JSON path ($.[*]) to split the content into JSON elements within the JSON array([]).
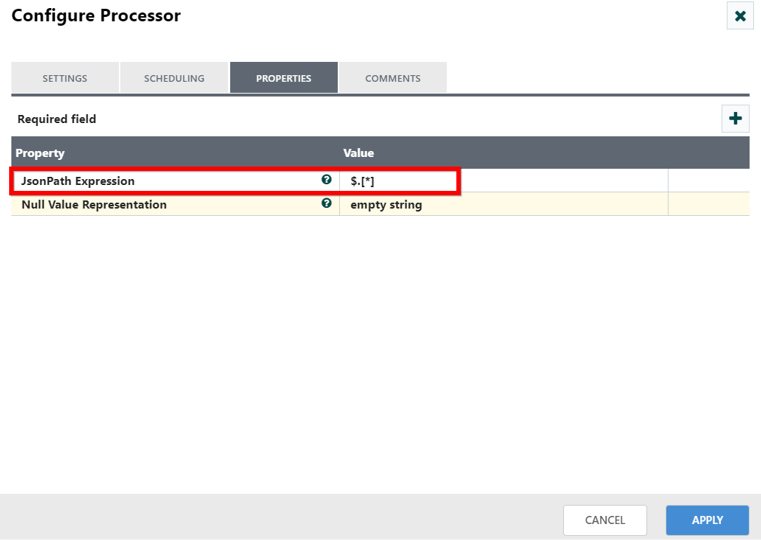
Output of the JSON element after splitting the JSON array:

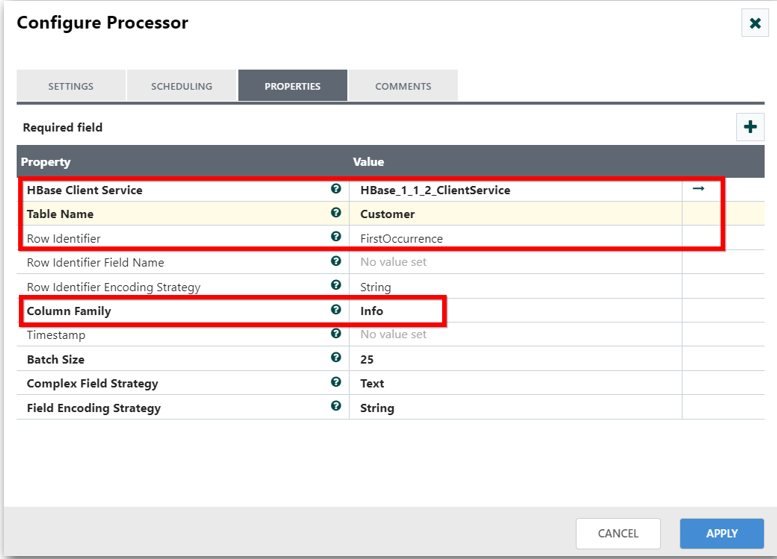
Step 3: Insert the JSON data into the HBase table
Drag and drop the PutHBaseJSON processor and create the HBase_1_1_2_ClientService controller service to connect with HBase.
Also, specify the following properties to insert the JSON data into the HBase table.
Table Name: <Your HBase table name>
Row Identifier: <Specify any attribute in the flow files>
Column Family: <Your HBase table column family>
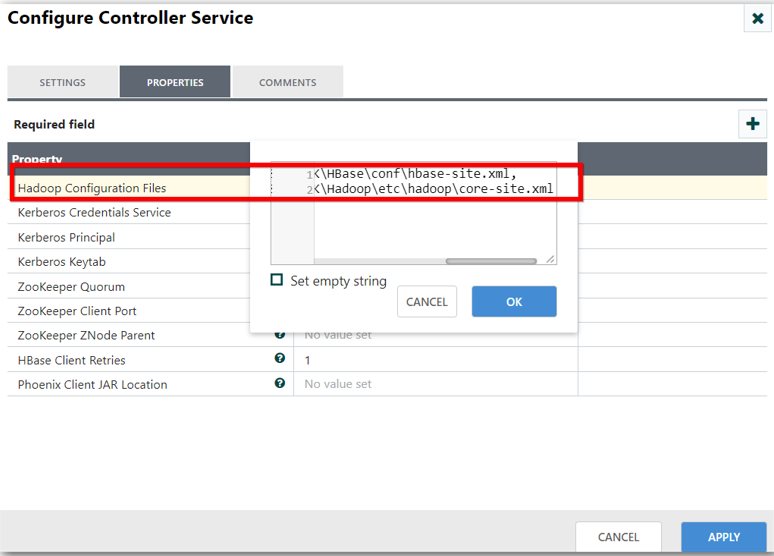
HBase_1_1_2_ClientService configuration:
Specify the file paths of hbase-site.xml and core-site.xml files of HBase and Hadoop packages in the Hadoop Configuration Files property.
Enable the controller service:

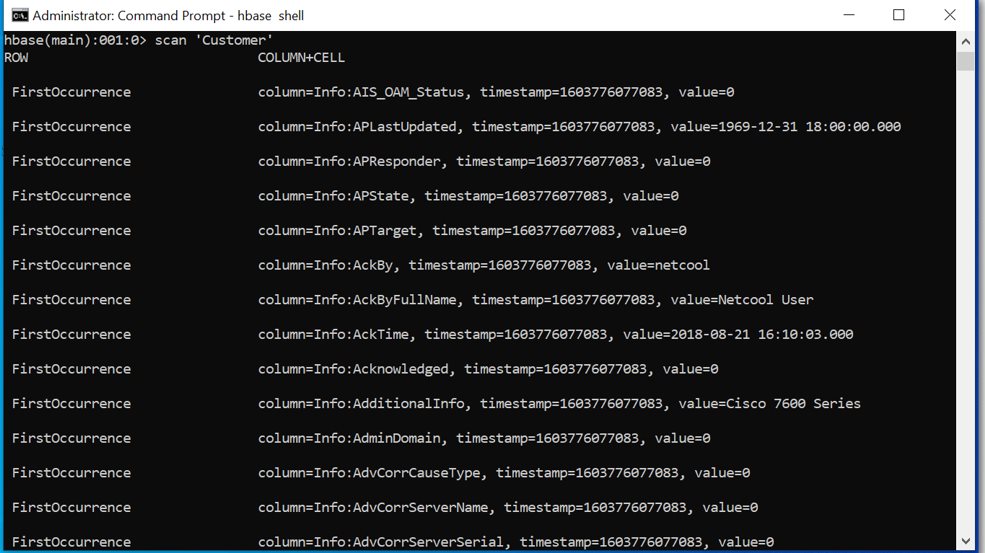
Output: