Description and usage of GenerateTableFetch:
Generates SQL select queries that fetch “pages” of rows from a table. The partition size property, along with the table’s row count, determine the size and number of pages and generated FlowFiles. In addition, incremental fetching can be achieved by setting Maximum-Value Columns, which causes the processor to track the columns’ maximum values, thus only fetching rows whose columns’ values exceed the observed maximums. This processor is intended to be run on the Primary Node only.
Tags:
sql, select, jdbc, query, database, fetch, generate
Properties:
In the list below, the names of required properties appear in bold. Any other properties (not in bold) are considered optional. The table also indicates any default values, and whether a property supports the Expression Language Guide.
|
Name |
Default Value |
Allowable Values |
Description |
| Database Connection Pooling Service |
Controller Service API:
DBCPService Implementations: HiveConnectionPool DBCPConnectionPool |
The Controller Service that is used to obtain a connection to the database. | |
| Database Type | Generic |
*Generic  *Oracle |
The type/flavor of database, used for generating database-specific code. In many cases the Generic type should suffice, but some databases (such as Oracle) require custom SQL clauses. |
| Table Name | The name of the database table to be queried. | ||
| Columns to Return | A comma-separated list of column names to be used in the query. If your database requires special treatment of the names (quoting, e.g.), each name should include such treatment. If no column names are supplied, all columns in the specified table will be returned. | ||
| Maximum-value Columns | A comma-separated list of column names. The processor will keep track of the maximum value for each column that has been returned since the processor started running. Using multiple columns implies an order to the column list, and each column's values are expected to increase more slowly than the previous columns' values. Thus, using multiple columns implies a hierarchical structure of columns, which is usually used for partitioning tables. This processor can be used to retrieve only those rows that have been added/updated since the last retrieval. Note that some JDBC types such as bit/boolean are not conducive to maintaining maximum value, so columns of these types should not be listed in this property, and will result in error(s) during processing. If no columns are provided, all rows from the table will be considered, which could have a performance impact. | ||
| Max Wait Time | 0 seconds | The maximum amount of time allowed for a running SQL select query , zero means there is no limit. Max time less than 1 second will be equal to zero. | |
| Partition Size | 10000 | The number of result rows to be fetched by each generated SQL statement. The total number of rows in the table divided by the partition size gives the number of SQL statements (i.e. FlowFiles) generated. A value of zero indicates that a single FlowFile is to be generated whose SQL statement will fetch all rows in the table. |
Relationships:
|
Name |
Description |
| success | Successfully created FlowFile from SQL query result set. |
| failure | This relationship is only used when SQL query execution (using an incoming FlowFile) failed. The incoming FlowFile will be penalized and routed to this relationship. If no incoming connection(s) are specified, this relationship is unused. |
Reads Attributes:
None specified.
Writes Attributes:
|
Name |
Description |
| generatetablefetch.sql.error | If the processor has incoming connections, and processing an incoming flow file causes a SQL Exception, the flow file is routed to failure and this attribute is set to the exception message. |
| generatetablefetch.tableName | The name of the database table to be queried. |
| generatetablefetch.columnNames | The comma-separated list of column names used in the query. |
| generatetablefetch.whereClause | Where clause used in the query to get the expected rows. |
| generatetablefetch.maxColumnNames | The comma-separated list of column names used to keep track of data that has been returned since the processor started running. |
| generatetablefetch.limit | The number of result rows to be fetched by the SQL statement. |
| generatetablefetch.offset | Offset to be used to retrieve the corresponding partition. |
State management:
|
Scope |
Description |
| CLUSTER | After performing a query on the specified table, the maximum values for the specified column(s) will be retained for use in future executions of the query. This allows the Processor to fetch only those records that have max values greater than the retained values. This can be used for incremental fetching, fetching of newly added rows, etc. To clear the maximum values, clear the state of the processor per the State Management documentation |
Restricted:
This component is not restricted.
Input requirement:
This component allows an incoming relationship.
See Also:
QueryDatabaseTable, ExecuteSQL, ListDatabaseTables
How to configure?
Step 1: Drag and drop the GenerateTableFetch processor to canvas.
Step 2: Double click the processor to configure, the configuration dialog will be opened as follows,
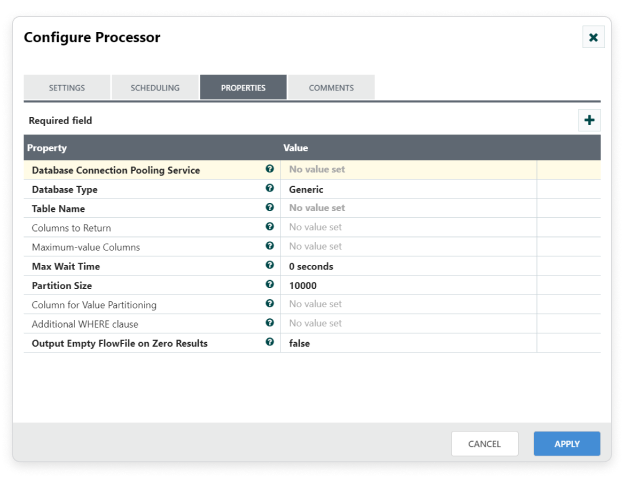
Step 3: Check the usage of each property and update those values.
Properties and usage:
Database Connection Pooling Service: The Controller Service that is used to obtain a connection to the database.
Database Type: The type of database, used for generating database.
Table Name: The name of the database table to be queried.
Columns to Return: A comma-separated list of column names to be used in the query. If no column names are supplied, all columns in the specified table will be returned.
Maximum value Columns: A comma-separated list of column names to be used in the query. If no columns are provided, all rows from the table will be considered.
Maximum Wait Time: Maximum amount of time allowed for a running SQL select query.
Partition size: The number of result rows to be fetched by each generated SQL statement.
Additional WHERE clause: A custom clause to be added in the WHERE condition when generating SQL requests.
Example:
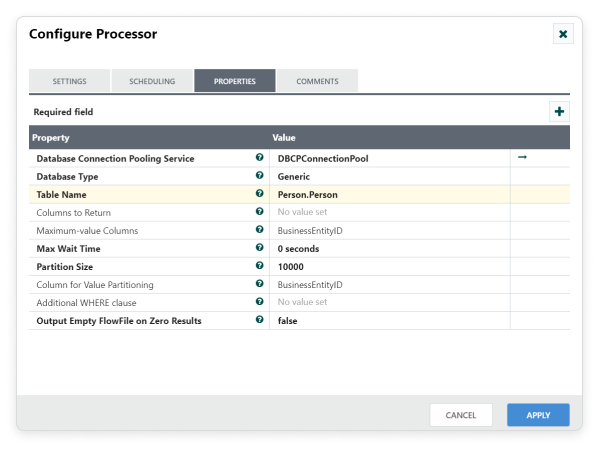
For example, to get the Person’s Data from the database table, configure GeneratefetchTable shown in the following screenshot,
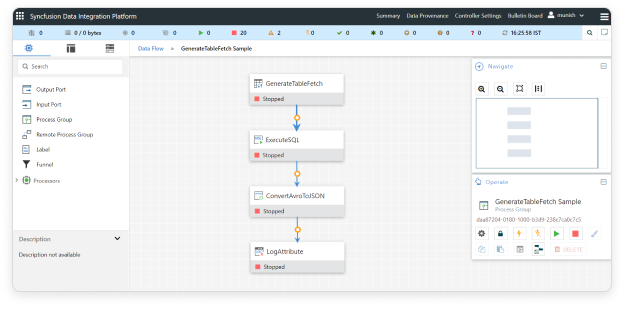
Sample Workflow:
This sample workflow uses the GenerateTableFetch processor to extract text from GenerateTablefetch and input it to ExecuteSQL in Data Integration platform.
List of processors used in this sample:
|
Processor |
Comments |
| GenerateTableFetch | Gives incremental SQL statements based on partition size. |
| ExecuteSQL | Executes all the SQL statements that got generated by GenerateTableFetch processor. In Data Integration Platform every ExecuteSQL processor results default format is Avro. |
| ConvertAvroToJSON | Converts all the Avro data to JSON data. |
| LogAttribute | Fetch the queued flow data. |
Workflow screenshot
Step 1: Configure GenerateTableFetch processor
Drag and drop the GenerateTableFetch processor to the canvas area. GenerateTableFetch Gives incremental SQL statements based on partition size. Configure Database Connection Pooling Service and other required properties in configuration dialog as shown in the following screenshot.
Step 2: Configure ExecuteSQL processor
Drag and drop the ExecuteSQL processor to the canvas area. ExecuteSQL processor can be used to Executes all the SQL statements that got generated by GenerateTableFetch processor. Configure Database Connection Pooling Service and other required properties in configuration dialog as shown in the following screenshot. Once configured, make connection between ExecuteSQL and GenerateTableFetch with ‘Success’ relationship.
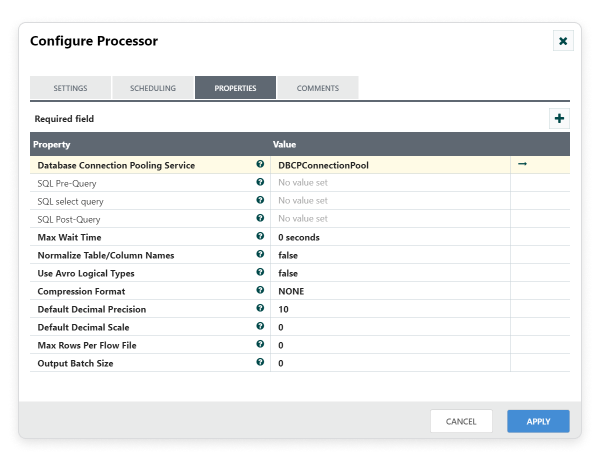
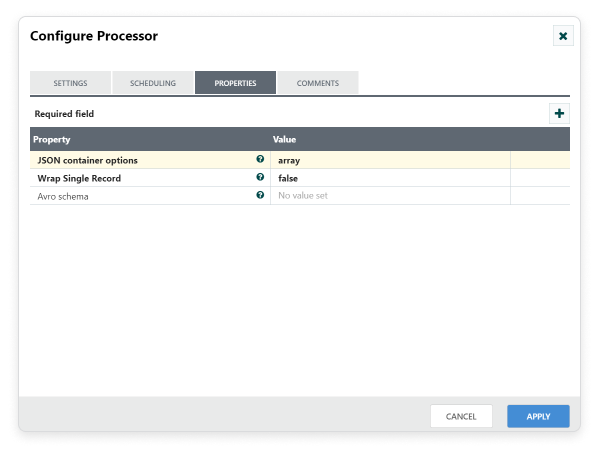
Step 3: Configure ConvertAvroToJSON processor
Drag and drop the ConvertAvroToJSON processor to the canvas area. ConvertAvroToJSON used to Converts all the Avro data to JSON data once we get Avro data from ExecuteSQL. Configure required properties in configuration dialog as shown in the following screenshot. Also make connection between ExecuteSQL and ConvertAvroToJson with ‘Success’ relationship.
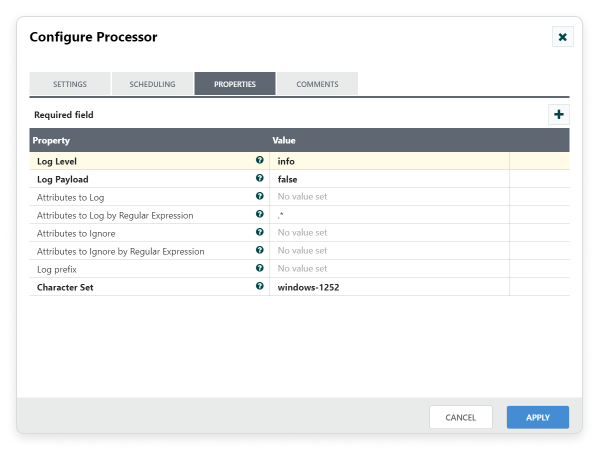
Step 4: Configure LogAttribute processor:
Drag and drop the LogAttribute processor to the canvas area. LogAttribute processor can be used to fetch the queued flow data. From that, we can investigate the contents and provenance of the queued flowfiles. Configure required properties in configuration dialog as shown in the following screenshot. Also make connection between ConvertAvroToJSON and LogAttribute with ‘Success’ relationship.
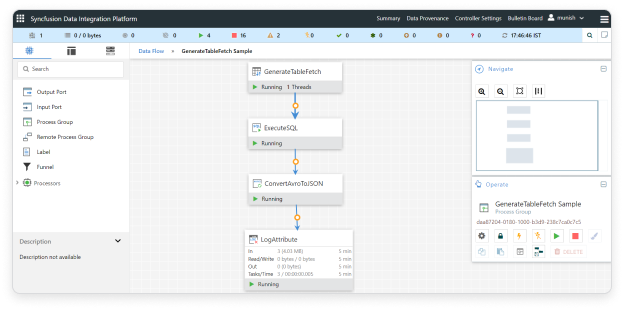
Step 5: Starting workflow
Once all processors are configured, start the workflow. You can see the data flow through the processors.
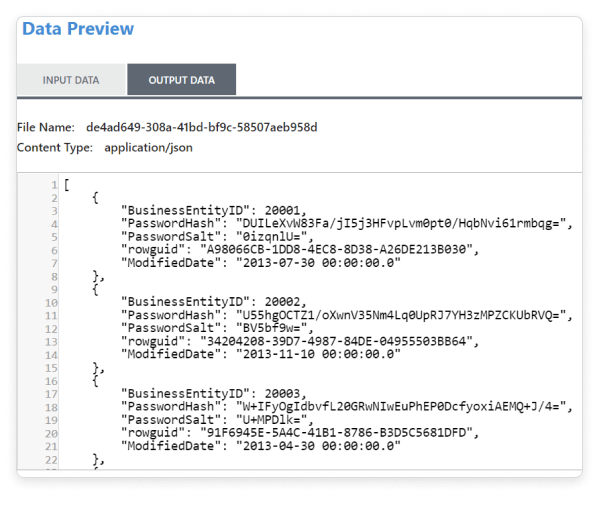
Output data:
Right Click on the LogAttribute Processor and select Data preview, you can see the converted JSON Output Data.