HBase and Spark Performance Tuning
This section provides information on tuning HBase and Spark based on available machines and its hardware specification to get maximum performance.
Spark
Apache Spark is very resource intensive so you need to be careful in appropriately allocating YARN and Spark resources to achieve expected performance. Each Spark application consists of a single driver process and a set of executor processes scattered across the nodes on the cluster. Each Spark executor in an application has a number of cores and a heap size. In order to obtain high throughput, you have to specifically set the number of instances, cores, and heap size used by executors.
The recommended configuration for tuning will be illustrated based on the following hardware specification.
| RAM | 16 GB |
| Hard Disk | 500 GB |
| Number of Cores | 8 |
| Operating System | Windows Server 2012 |
Number of nodes used in the Hadoop cluster: Two Name nodes and three Data nodes.
Performance tuning and optimization
At the outset we used the configuration settings listed in the following table.
Configuration file: Yarn-site.xml
| Property name | Property value |
|---|---|
| yarn.nodemanager.resource.memory-mb | 14336 |
| yarn.scheduler.minimum-allocation-mb | 1024 |
| yarn.scheduler.maximum-allocation-mb | 6144 |
- yarn.nodemanager.resource.memory-mb: Maximum RAM size in MB can be allocated for yarn utilization on each node of the cluster.
- yarn.scheduler.maximum-allocation-mb: Specifies the minimum allocation of memory to create container on each node.
- yarn.scheduler.maximum-allocation-mb: Specifies the maximum allocation of memory to create container on each node.
From the previously mentioned yarn configuration, maximum of 14GB from RAM memory has been allocated for map reduce job utilization and remaining 2GB will be used by other application and OS.
This section explains how to calculate the spark configuration with the previously mentioned hardware specification. The following three properties runs the spark job efficiently by utilizing the cluster nodes properly.
- To run multiple task’s in JVM and also considering hadoop daemon’s to run smoothly, assign (8 core/ 3) core per executors therefore spark.executor.cores = 2 (for good HDFS throughput)
- Available core per node is calculated by leaving 1 core for Hadoop or yarn daemon’s from actual core count on each data node of the cluster that is 8 core - 1 core = 7 core.
- Total available core of the cluster is calculated by ( Available core per node * number of data nodes) that is (7 core * 3) = 21 core.
- Number of Available executors is (Total available core / core per executor) that is (21 core / 2 ) gives spark.executor.instances = 10
- Number of Executors per node is (Available executor / number of data nodes) that is (10/3) = 3
- Memory per Executors is ( RAM size of each node / Number of executors) that is ( 16 GB / 3) = 5 GB
- Executor Memory is calculated by considering heap size as 7% of Memory per Executors that is (7% of 5) = 0.35 GB therefore spark.executor.memory = 5 - 0.35 = 4.65 GB
- Driver Memory is used by spark RDD, it is default 1g upto 60% of executor memory.
NOTE
This setting may affect the performance of other type of Hadoop jobs like MR, Pig, and Hive jobs when spark jobs are actively running.
Configuration file: spark-defaults.conf
spark.driver.memory 3g
spark.executor.memory 4g
spark.executor.instances 10
spark.executor.cores 2
In addition, remove the spark.cleaner.ttl property from the configuration information to avoid clearing
cached data.
The above recommended configuration of YARN and Spark can be done using cluster manager by following below steps:
YARN configuration
Step 1: Click Configuration option under Administration menu and select Hadoop service.
Step 2: In the same yarn-site.xml, add the following two new properties to set minimum and maximum size for requesting containers.
| Property name | Property value |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 1024 |
| yarn.scheduler.maximum-allocation-mb | 6144 |
Spark configuration
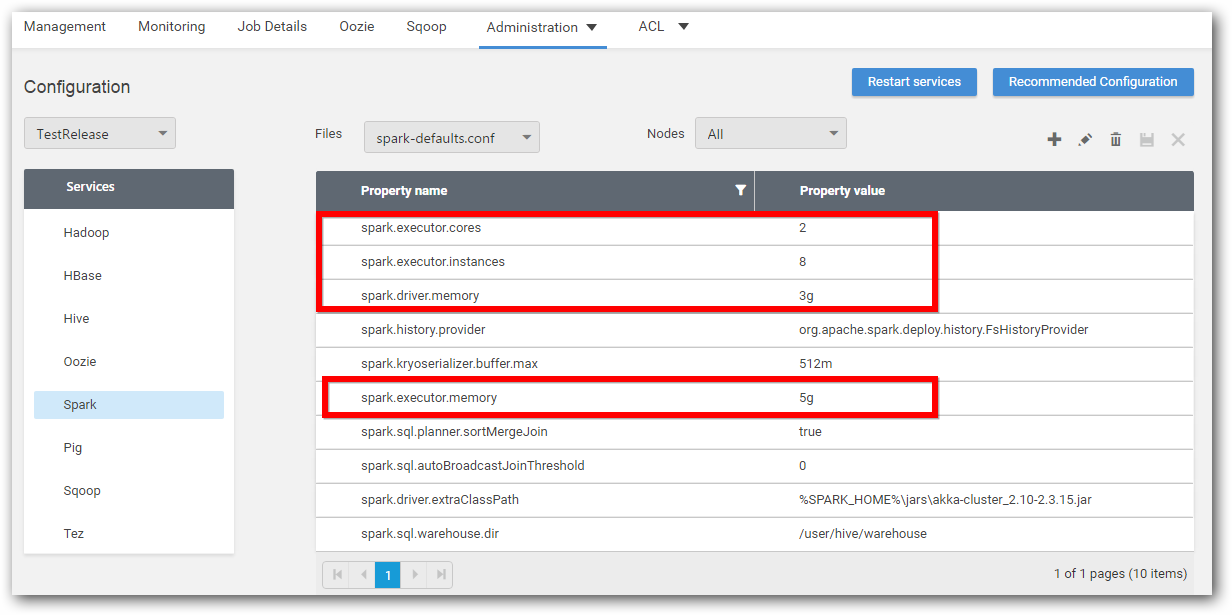
Step 1: Select Spark from services and select spark-defaults.conf file.
Step 2: Edit spark.executor.memory property’s value as 5g.
Step 3: In the same file spark-defaults.conf, add the following new properties and remove the spark.cleaner.ttl property.
| Property name | Property value |
|---|---|
| spark.driver.memory | 3g |
| spark.executor.memory | 4g |
| spark.executor.instances | 10 |
| spark.executor.cores | 2 |
Step 4: Save the changes and click restart services to apply the changes in the cluster.
HBase
Common problem when running HBase cluster in a high-velocity load (Like handling massive amounts of time-series data) is that often HRegionServer’s shutdown due to GC “stop-all allocation” pause.
This pause occurs when JVM heap memory gets filled due to high traffic in incoming data.
To prevent a “GC complete” pause from occurring, we tuned the JVM to perform garbage collection more efficiently using the following settings:
- UseConcMarkSweepGC
- UseParNewGC
- CMSInitiatingOccupancyFraction=60
The key idea here is that we request the garbage collection system to start collecting before there is potential for completely running out of memory.
For more details, please refer to the Oracle documentation on memory management.
Follow below steps in Cluster Manager Application to set these configurations.
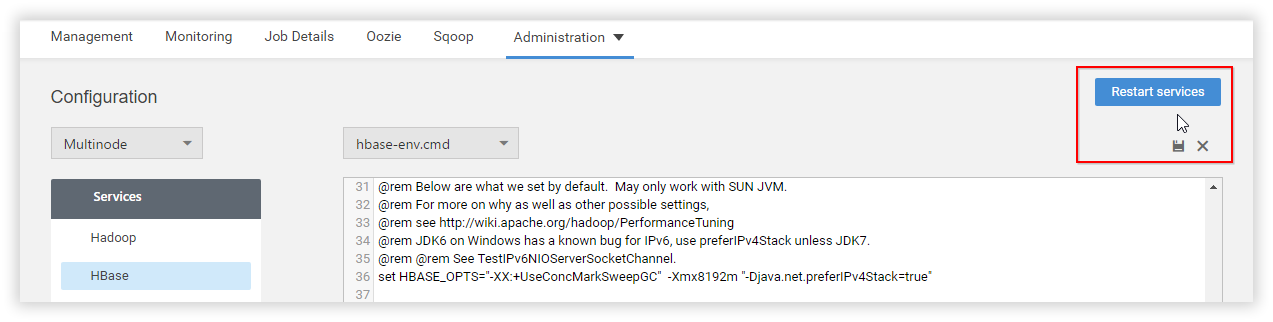
Step 1: Click Configuration option under Administration menu.
Step 2: Select HBase from services.
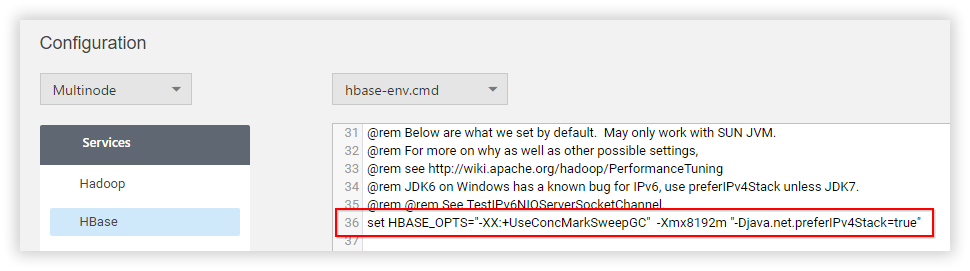
Step 3: In hbase-env.cmd file, set the JVM flags in HBASE_OPTS as,
HBASE_OPTS="-XX:+UseConcMarkSweepGC" "-XX:+UseParNewGC" "-XX:CMSInitiatingOccupancyFraction=60" -Xmx1024m
NOTE
Here we have set 8 GB as heap memory where machine’s primary memory is assumed to be 16 GB.
Step 4: Save the changes and click Restart services to apply the changes in cluster.